


Understanding the difference between a fact table and a dimension table can help you store and analyze your data more efficiently.
But what is a fact table and what is a dimension table?
Basically, fact tables store measurable data (like numbers and values), while dimension tables contain descriptive information that gives context to the data in the fact table. Numbers on their own sometimes don't have much meaning, but when you combine them with dimension tables, you get context and insight.
Let’s look at an example:
Suppose we have a table that contains information about which customer bought which product, how much they paid, and how many units of the product they purchased.
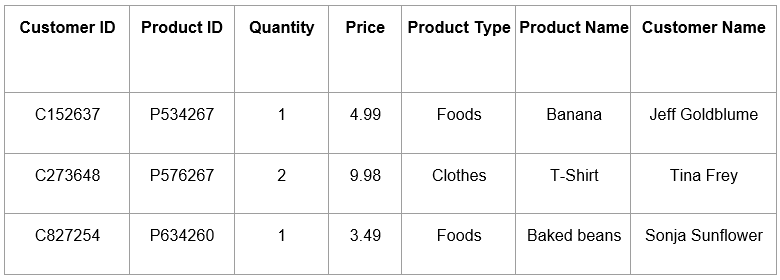
We could store all this information in one large table, as shown above, but that wouldn’t be very efficient. So instead, we store the measurable values in the fact table:
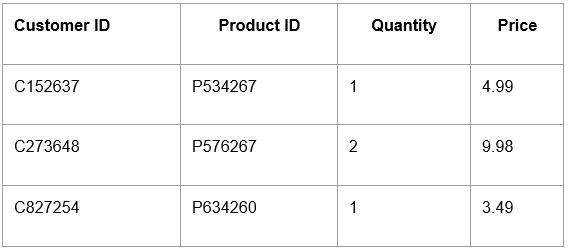
Now this fact table stores the core transactional data.
The Dimension table contains additional information that gives context to the information in the fact table. For example, the Product ID in the fact table doesn’t tell us much by itself. That’s why we link it to a dimension table that contains more detailed information about each product.
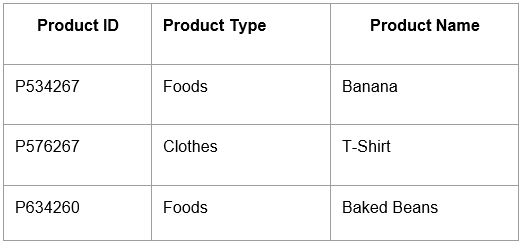
This way, we have all key measurements in the fact table, and through the dimension table, we can get additional information — like which specific product was bought. The Product ID serves as a primary key, linking the two tables.
We can apply the same principle to further information in the fact table, for example a dimension table containing information about the customer (e.g. the Name). This would result in a schema that looks like a star:
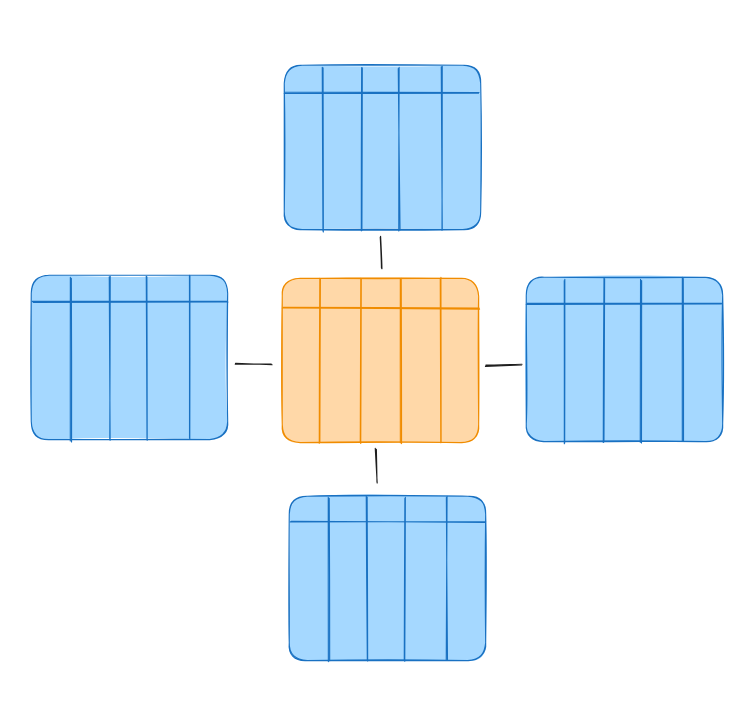
• Orange = The central fact table
• Blue = Several surrounding dimension tables
In some cases, a dimension table may reference another dimension table — this results in a structure known as a snowflake schema, because the schema diagram resembles a snowflake.
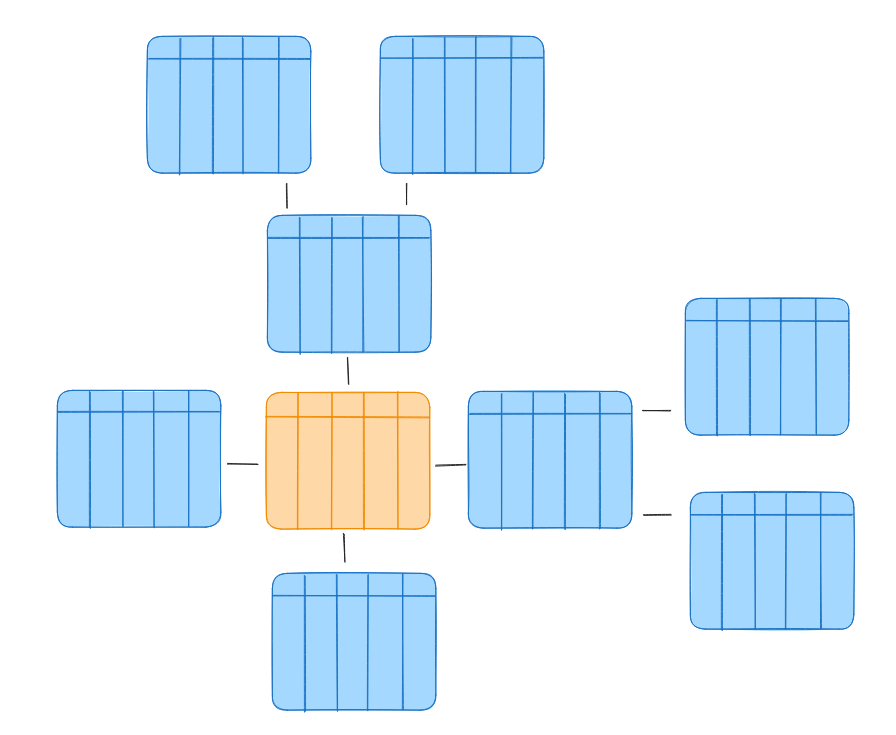
With this schema, we have the important information all in one view and can access additional information when we need it.