


Motivation
This is a 16-week project to analyse 16 years (and $400 billion!!) of funding by the National Institutes of Health (NIH), the largest organisation funding biomedical research. I’ll built it incrementally, each week applying only elements we have covered in the data school that week (and previously). The idea is to follow the progress of the training that will allow the incorporation of new techniques/ideas to the analysis.
Without further ado…
Week 1
Objective: to examine if the funding allocated to the different states reflects the national per capita funding or if there are some states that receive disproportionally high/low funding using the following formula:
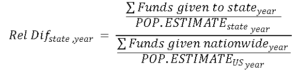
This will be one single dashboard built with three main items: calculations (including table calculations and a first dip in level of detail expressions), maps, and joining and blending.
The workbook is at TableauPublic. I started from 2 tables:
- Table 1 (main) contains the data downloaded from NIH reporter
- Table 2 contains the estimated population by state and year obtained from the US census.
First step: left join – adding the state population that year to the main table.
Second step: create an extract to improve performance.
Third step: create the calculations…
- Regular calculations: i.e. % of percapita = [Per Capita State]/[Per Capita Total]
- Level of detail calculations: i.e. Yearly total funding = { FIXED [FY] : SUM([Total Cost])}
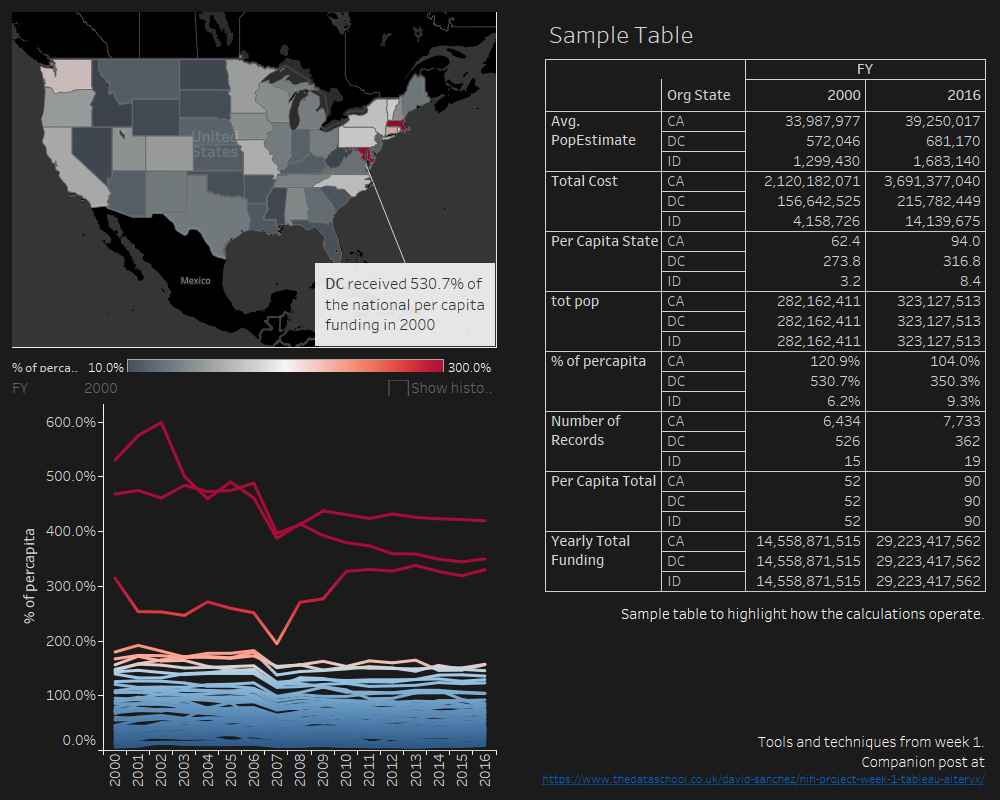
Finally, plot the yearly map and a summary graph that clearly shows the disparity in the per capita funding between different states, as well as a sample table to understand how the different calculations operate. Taxation without representation… but, combined with Maryland and Massachusetts, the District disproportionally receive funding for biomedical research from NIH in a per capita basis (whereas Idaho just receives 5% of the national per capita funding)…
Data Sources:
NIH funding data came from the ExPORTER catalog.
US state population was obtained from US census estimates (2000-2010 & 2010-2016)
Data wrangling was done using python and pandas. Main steps:
- Combine all files into a single dataframe
- Combine and discard sub-projects (assigned to the main project & PI)