Today at the Data School we have been assigned projects testing our ability to interrogate APIs.
I was assigned The Cocktail DB website, and I was asked to interrogate the API to return all the drinks for each category and information about each drink. Initially, I spent some time looking for information about the features and functionalities of the API. There is no official documentation on the website, but there are some instructions and suggested requests listed.
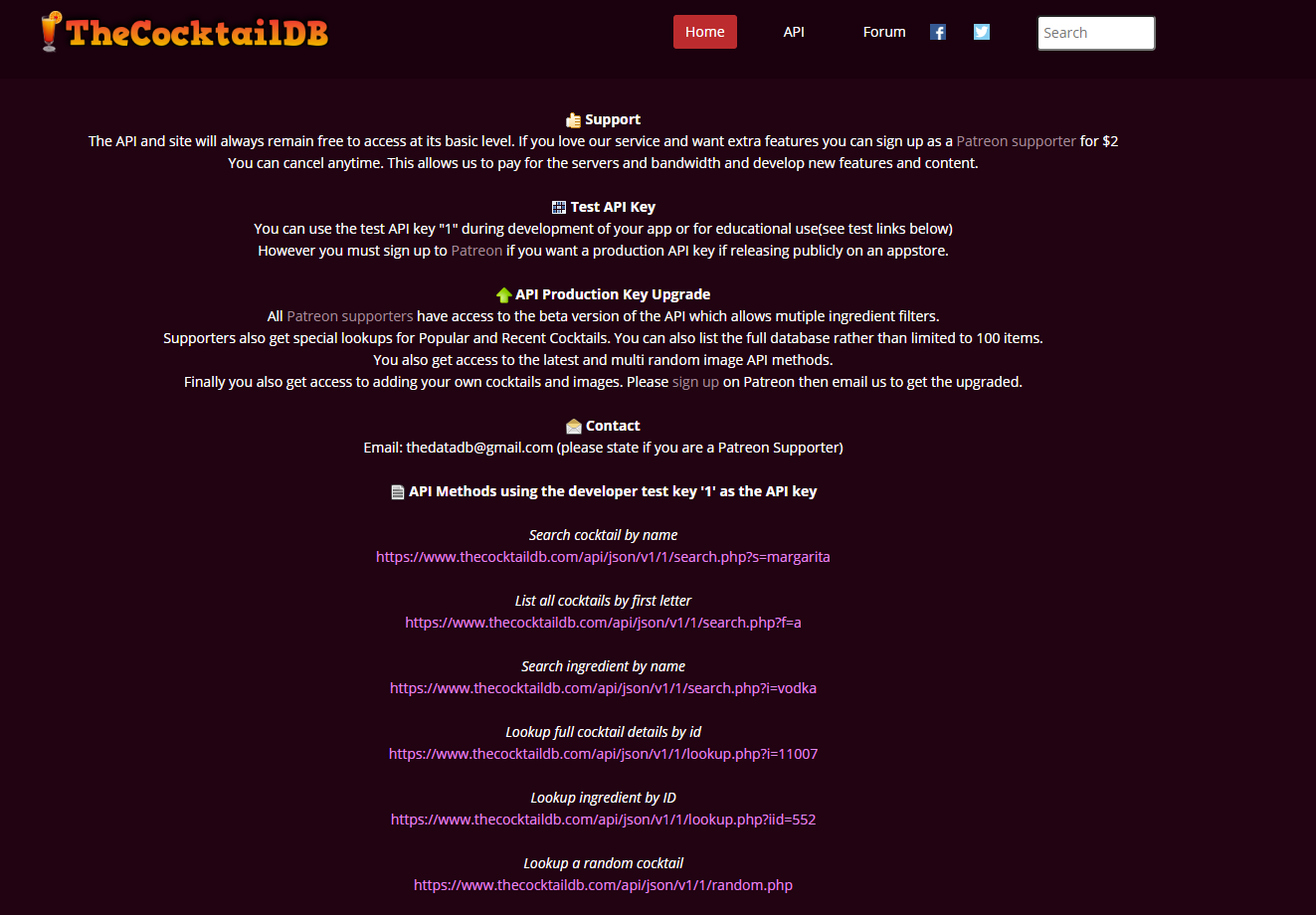
There is also a link to a forum which has been active since 2015 where the creator presented the project and along with many users they have been discussing the features and limits, and working on improvements. Unfortunately, it is not always clear whether the improvement discussed have been implemented or what changes have been introduced. Skimming through the forum posts, I found that there are many limitations implemented for performance reasons: it is possible to retrieve only lists shorter than 250 entries, so it is not possible to retrieve the complete list of cocktails at once, and some information in the database needs to be normalized. For example, a user pointed out that things like the ingredients are not listed consistently and suggests these might need to be merged.
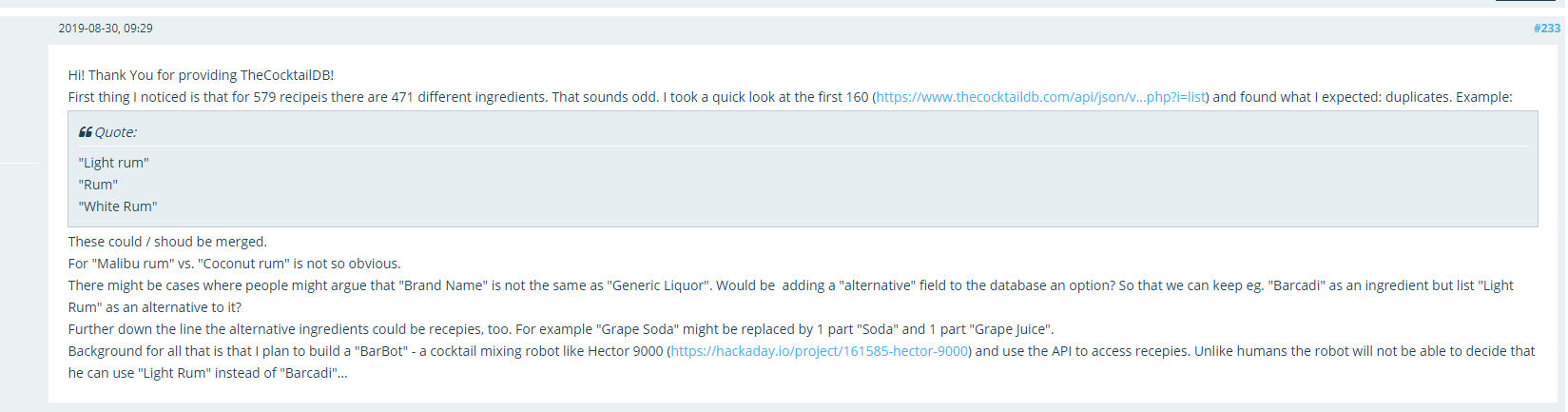
Some issues have been found in the search for ingredient, too:
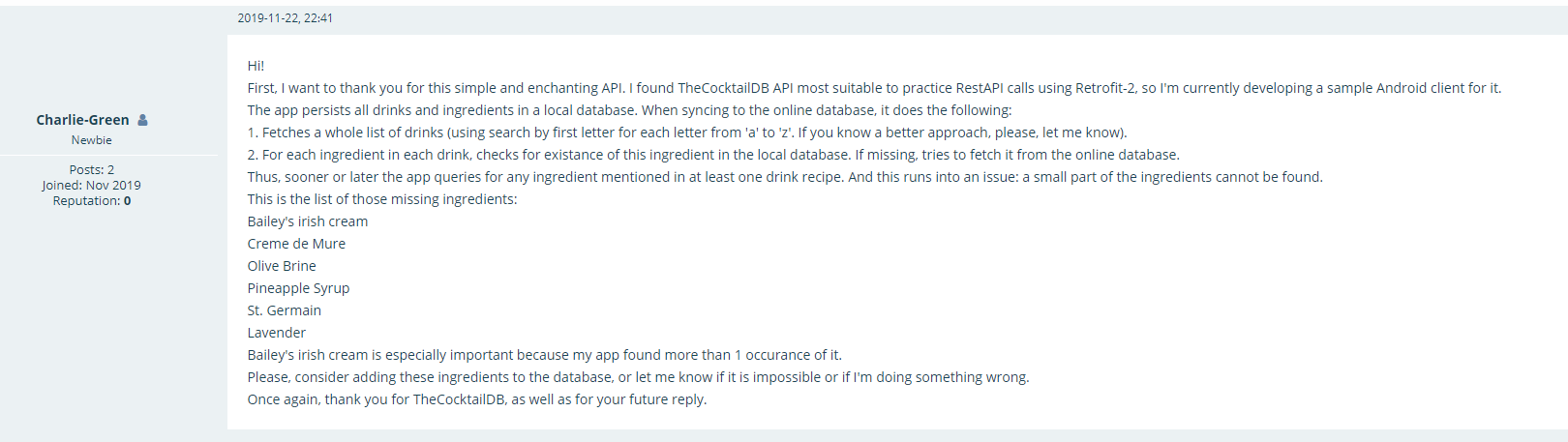
Again, it is not clear how these issues have been fixed, the only way to find out if a query is acceptable is running it. This system has some flaws since it is impossible to see which records have been excluded from the results. This happened when I tried to interrogate The cocktail DB for a list of drink by category: there are two example of categories used, but when I tried to come up with similarly formatted URLs for the other categories, I did not get all the results I was expecting. I created a list of categories, and used this to customise the URLs. For some categories there are no results, and it is probably because of the URLs I customized (trying to paste and search these addresses in a browser did not return any json).
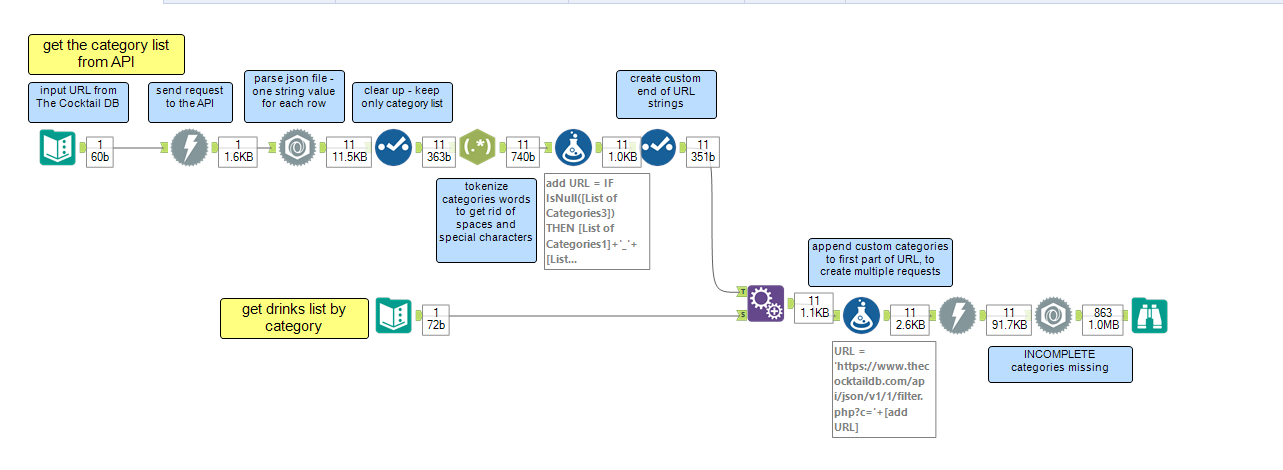
Therefore, instead of trying and think about different possible combination of categories or letters/characters to include in the URLs, I went for another way. It is possible to interrogate the API to return a list of cocktails by the first letter of their name, so I manually populated a text input tool with all the letters and numbers, to use in the query. I figured this way would be less susceptible to mistakes or casual combination of categories and character than the previous solution.
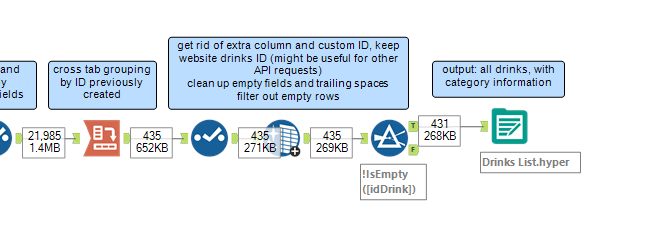
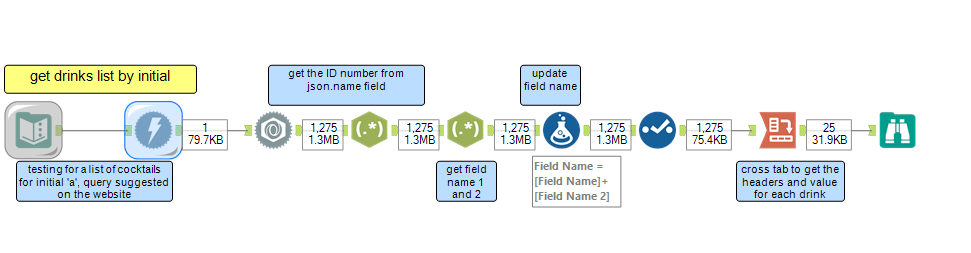
First, I tested the query sending a single request for drinks with name initial ‘a’ – a query suggested on The Cocktail DB website, hence I was pretty sure it would work – and created a workflow to see what the data would look like. After running the download and json parse tools, I wrote a regex to parse the ID number for the cocktail from the json name field, so that it would be easier to group all the information together lather on. I also used regex and a formula tool to create my headers. With a cross tab tool is easy to group the data by the ID created. Now I have a row for each drink.
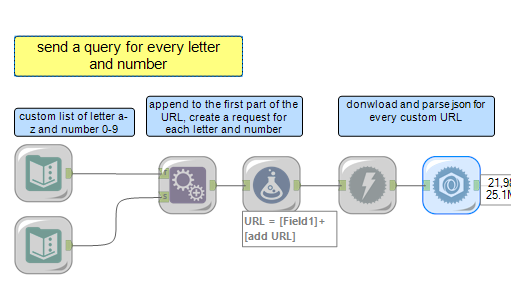
Now, to retrieve a complete list of all the cocktails in the database, I can run this workflow for every letter and number that might be the initial of the name of the drinks in the database. With a text input tool, I created a list of letters a-z and numbers 0-9, which I could then append to the first part of the URL for the API request. A request to the API will be sent for every custom URL created. At this point I am looking at 21985 rows, every row being an information on a specific drink.
To organize my results, I decided to replicate the regex parsing to get the ID from json.name, and to pair this with the relative letter or number from the field used to generate the custom URLs to create unique identifiers: this is a necessary step as every request from the API starts counting the drinks returned from 0, but having ID=0a, 0b, 0c, … will make possible to use the crosstab tool as before in the test workflow. Now I can get the field names for my headers, and I can clear the table from the columns I do not need anymore.
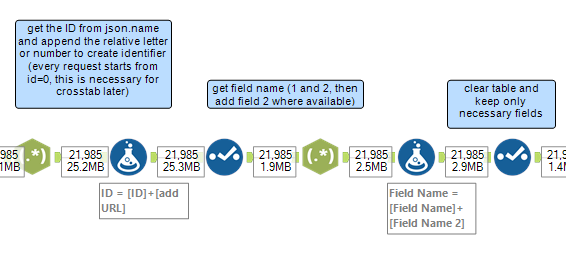
The last steps are about setting the crosstab tool to get a row for every drink and clean up: getting rid of unnecessary columns (I also got rid of the custom ID and decided to just keep the website’s drinks ID – they might be useful for other API request), cleaning trailing spaces and filtering out empty rows: the outcome is a table or 431 rows, one for each drink, with information about the name, category, ingredients and instructions for the preparations. Go get the glasses ready!