


New day, new task: today we are asked to download some data from the World Bank API upload data in Snowflake.
Full disclosure, I never heard of it before in my life, so I had to learn everything today. I will do my best to share with you my experience.
Which is why I went to look at a couple of introductory videos and resources online before diving in. The YouTube channel is a great place to gain some more understanding, there is also a 'get started' series of videos.
So what did I learned today? That SF is a data cloud. Which means that data can be stored, accessed, shared from the same place. To my understanding, SF looks like a platform to manage database and tables, it is possible to upload resources from different environments, and the tables can be interrogate with SQL queries. They can be then downloaded as new datasets, too. Let's see how to do that:
Create a Snowflake account
Sign up on the website, there is a trial account available for 30 days. After the account has been verified, there a couple of sample prepopulated DBs, but I also created a DB for my project, which will be later be populated with tables. This is the view from the Database panel:
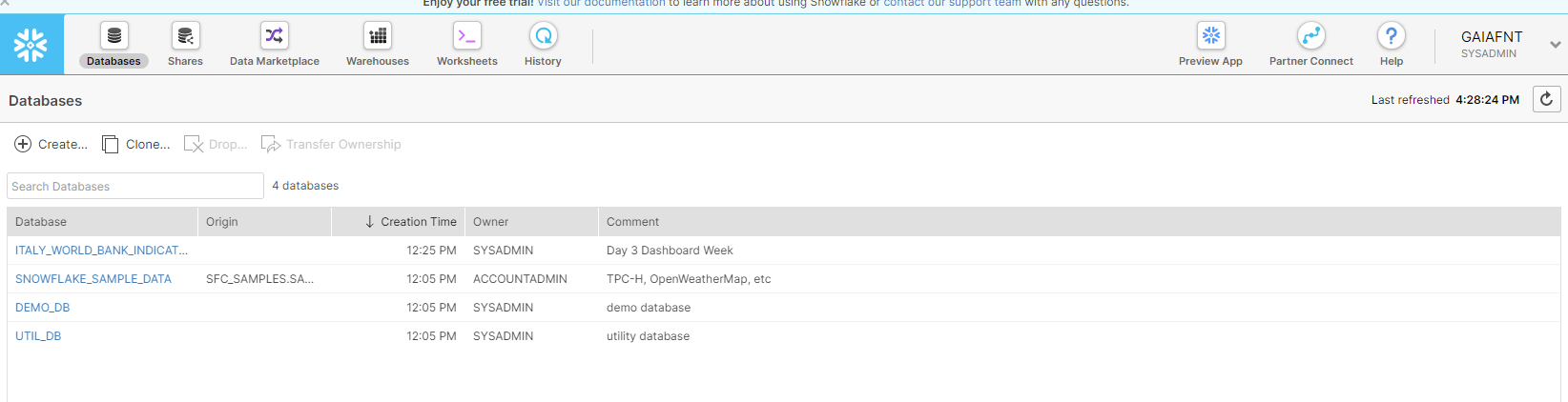
Now I need to go back to Alteryx and collect some data to upload.
Interrogate the API
I already talked about how to interrogate APIs with Alteryx in a previous blog post, so if you want to know more about this check it out. Briefly, for today's task, the process is very similar: I created a list of custom URLs, one for every indicator I wanted to get back, and I customised the query to collect only data for one country (Italy). I then filtered out the indicators that didn't include relevant values for the selected country and pivoted the table to have a row for every year. I now have a table of 61 rows (1960 to 2020) and 357 columns. Here's the complete workflow:

After creating my flow I needed to upload the table to SF so I first needed to edit a conenction and authenticate into SF. So I went into Alteryx Options > Advanced Options > Manage In-DB connections, and set the fields as follows:
- Datasource = Snowflake
- Connection Type = File
- Connection File = open the file in the folder where you store indbc files
- Password Encryption = Hide
- Read Driver = Snowflake ODBC
- Connection string: Paste the below
odbc:DRIVER={SnowflakeDSIIDriver};UID=<yourSFloginname>;PWD=<YourSFloginpassword>;DATABASE=;SERVER=Yourserverandregion>.snowflakecomputing.com and replace the <yourSFlonginname>, <YourSFlogninpassword> and <Yourserverandregion> with your details - Write tab > Driver > Same as read driver
- Select Ok
If you want to learn more about this step follow this link to a comprehensive article by The Information Lab.
Now I am ready to upload my table: past a output tool to the workflow and select Snowflake ODBC and set up a connection. Make sure you have downloaded and installed the necessary drivers that can be found here. Then go on and set up the connection as follow, insert your credentials, and the server address that can be found when you login into your SF account in the URL bar.
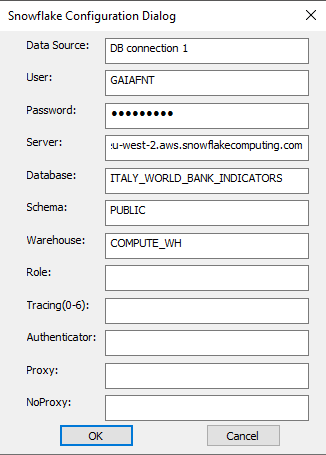
Go on and choose a file name, save the file and run the workflow. Done! Jump back into SF to find the table into the DB previously created.
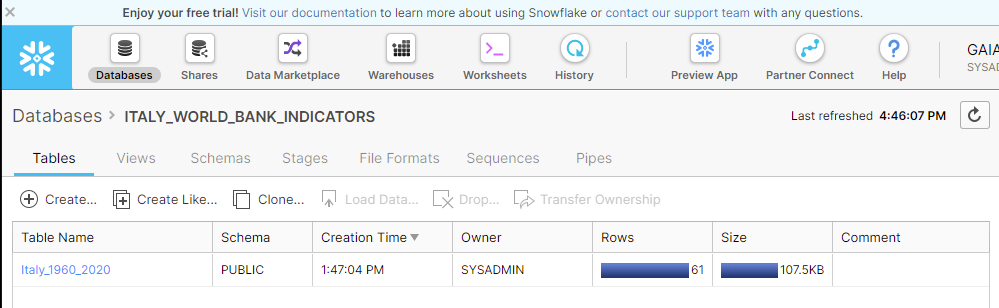
Now I can go into the worksheet tab and start querying the table. For this project I selected a few demographics indicators:
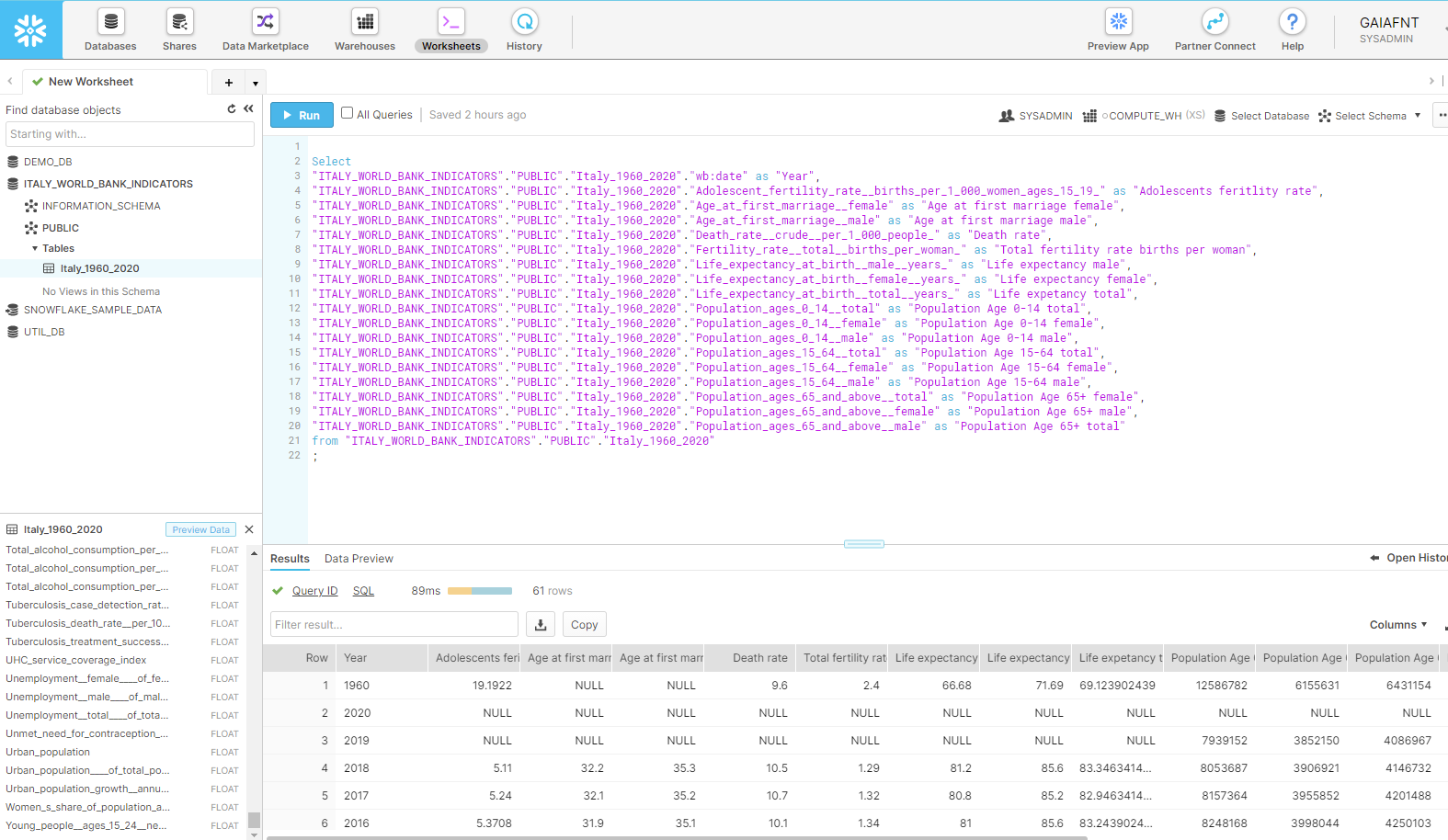
I also renamed the fields that imported a lot of special characters in the previous steps, so that the resulting file would be easier to read and understand. Now I can download from the little icon on top of the table, and I chose a .csv file so that it can be then imported in Tableau for a visual analysis.
That's it! It wasn't easy to jump from one environment to another in such a short amount of time today, but I think we all managed to get through the most of it succesfully, or at least we learn a lot trying!