


Struggling with Bike data
So for our last day in the DS, we were gifted a project to download bike data from the Seattle.Gov website, by Lorna to display in a dashboard before 13:30! It is safe to say that what started as a pretty miserable day weather-wise did not improve with this project!
Struggles #1
So what seemed as a fairly straight forward project quickly became a mammoth data prep challenge; my first port of call was to download 10 different .csv files into Alteryx to then prep the data. However, as a group we figured that this was a fairly static method, and it would be much better to future-proof this challenge and use the APIs to download all of the data.
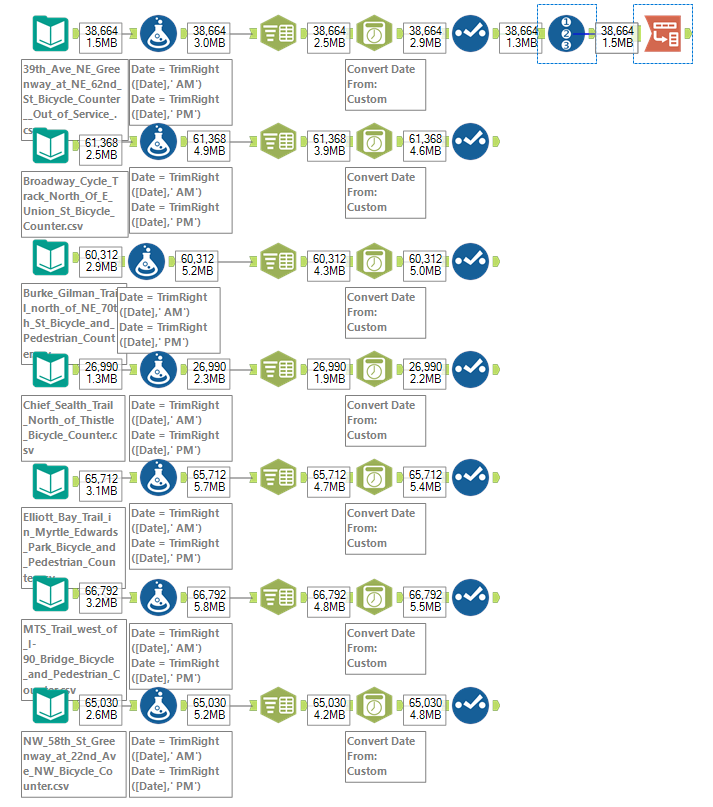
Struggles #2
Next: using the APIs to download the data. This was not too much of a problem, as we have worked with APIs many times before. I chose to have 10 different streams (one for each data file) because each file had differing number of fields. I know that you can input numerous APIs into one text input tool, however dealing with these files individually and formatting them into the same schema before unioning them made more sense to me. If I had more time, I would have made this into a macro for ease.
I thought at this point that my work in Alteryx was done. But, upon inspection, one of my colleagues noticed that each API was only calling a few thousand rows of the data (whereas there were tens of thousands of rows in some of the files). We should have come across this limitation a little bit sooner, but we didn't read the documentation well enough!
TOP TIP: Always read the documentation!
After realising that the only way around this was to apply for an API token from the Seattle.Gov website, I decided to go back into Alteryx, start again (for the third time) and use the download tool to download the .csv files.
Struggles #3
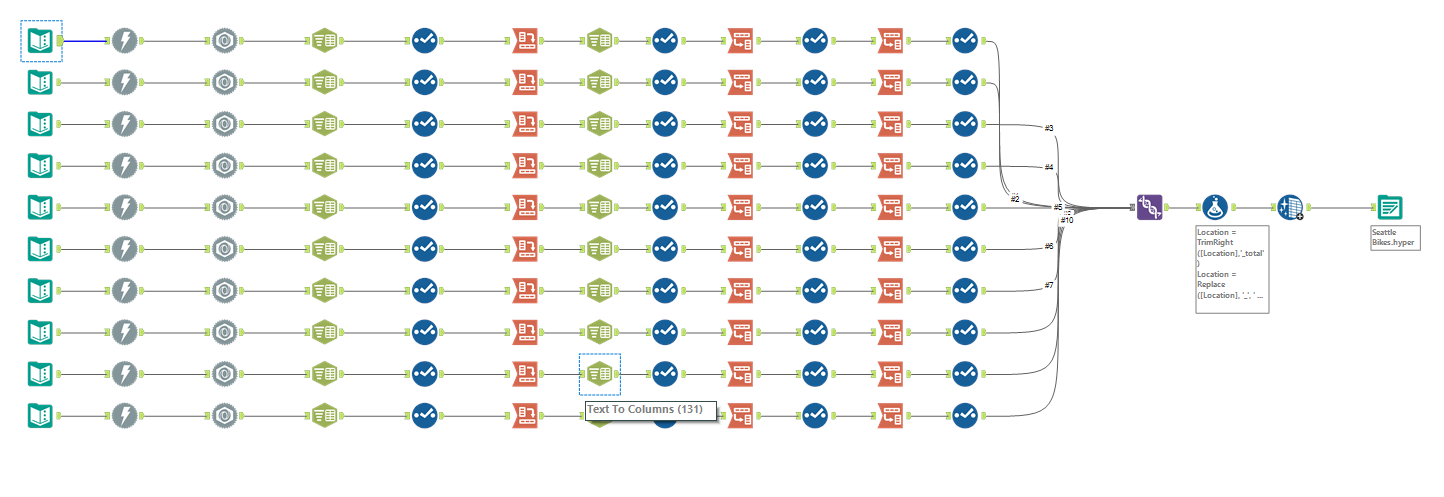
Finally a solution that has worked!
The above workflow details how I attempted to combine the different data files in Alteryx before outputting to a .hyper file to load up in Tableau. As you can see, there are now only 7 different streams, because I decided to drop 3 of the streams which were more difficult to find on the website due to time constraints (I wanted to get a finished workflow!).
The reason I had to deal with the separate streams again like this, is because each file had a different schema, so I couldn't get my head around how to deal with all of these at once. So I split each file up, renamed the fields with appropriate headers, and created a field called 'Direction of travel' because each data set either had in North bound and South bound travel, or East bound and West bound travel. Once the schemas for each file was identical, I unioned the data back together and outputted it into Tableau, after some final field renaming and data-type changes.
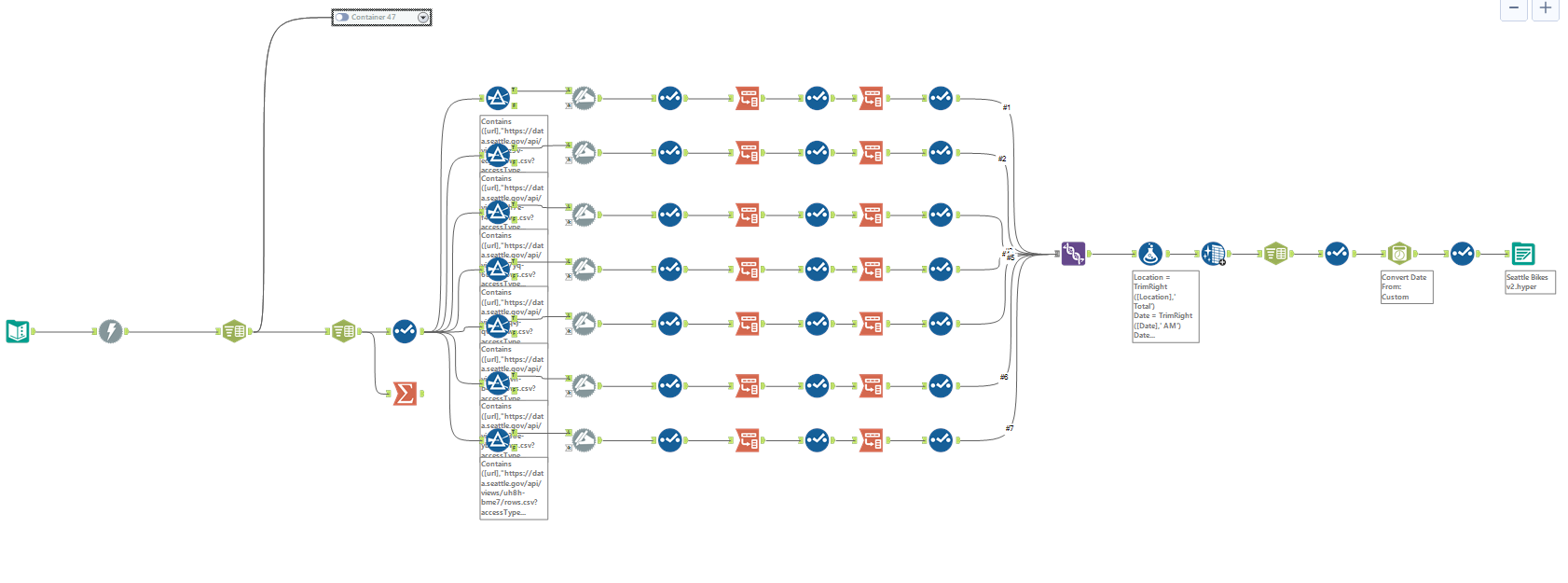
The unused container at the top was my first attempt at doing this, and can be seen below. My logic was to filter out just the column headers and deal with those separately before joining them back onto the rest of the data - however I realised quickly that this was not a valid solution.
Struggles #4
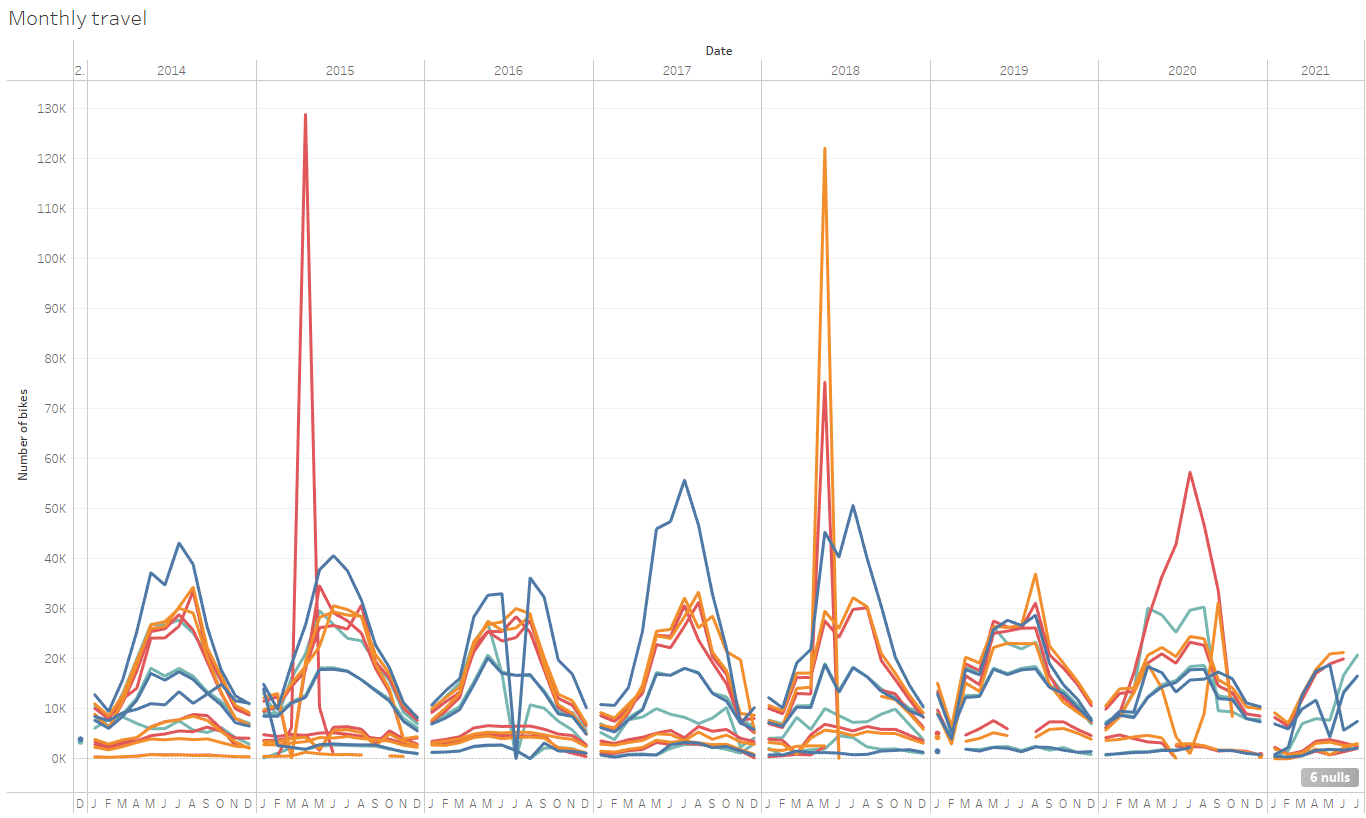
I managed to build two very basic charts after loading up my data into Tableau. These are below. I would really like more time to investigate the data, because there seems to be a huge spike in 2015 and May 2018 for the bike count data, which after a quick google I couldn't seem to find a reason for.
Challenges
The main challenges for this was the time constraint. However, we worked quite well as a team and managed to get a lot of work done. On reflection, I actually really enjoyed this project and have really enjoyed the whole of DS training!
So long DS24!
EDIT
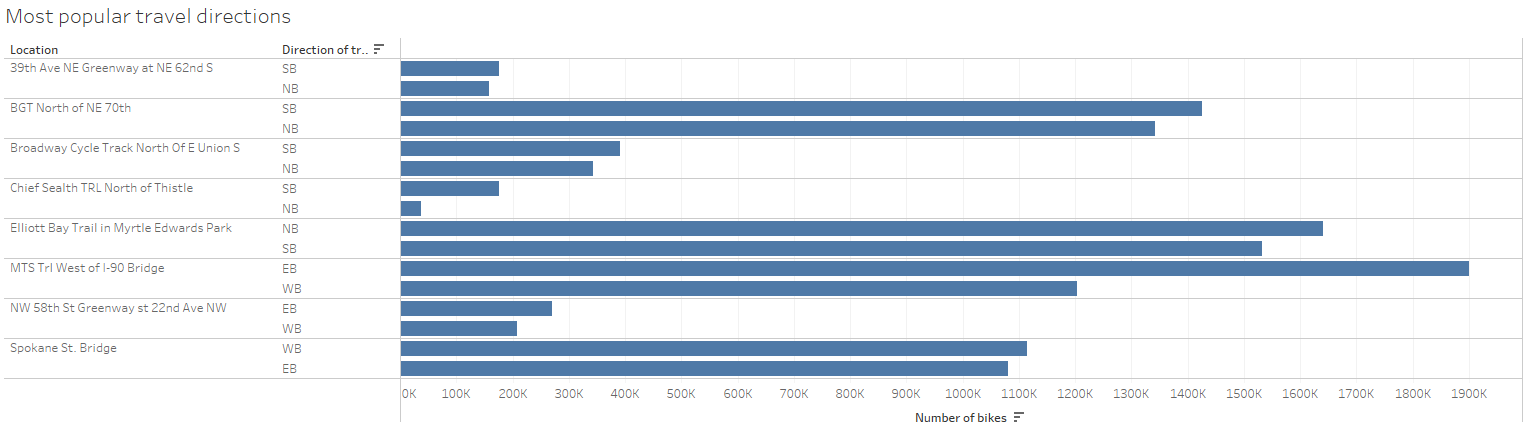
In a last ditched attempt to make a dashboard and to not annoy Andy, after our presentations I threw together some sheets about the volume of directional traffic in Seattle and put it on a dashboard which I uploaded to Tableau public!
