Today, our venerable Head Coach, Carl, gave us the project of doing as many Preppin' Data challenges as possible in 6 hours. The catch? All of these tasks have to be carried out entirely in SQL, using the Snowflake database setup we learned about only the day before. Whilst a daunting task, I launched myself into it head first, and through such a trial by fire, have ended up increasing my knowledge of SQL tenfold!
Inputting my Data through Tableau Prep
To bring data into Snowflake from Prep, I had to establish a connection between the two softwares. This began in Prep: first, I connected to the data locally, and then chose to Output the file as a Database table on Snowflake. This required a web connection, which is the URL link to my Snowflake (omitting the https://), and then OAuth sign-in. This then went through to options for my Warehouse, Database, Schema and Table Name (which I input myself, given I was importing new data). Running this then uploaded the table straight to Snowflake!
In Snowflake, it was then a case of aligning my Database and Schema with the table(s) I wanted to use data from, and I was all set up.
Preppin' Data 2021 W1
Week 1 of 2021 is a routine use case in Tableau Prep, but becomes far more complicated when using SQL. Presented with one column that needed splitting and then cleaning, I also had to build out two date part fields (Quarter and Day of Month), as well as removing the first 10 orders from the dataset.
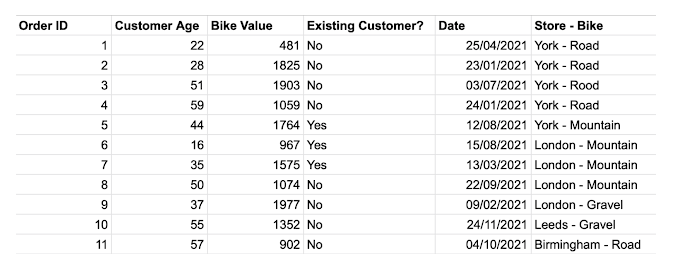
The latter half of this challenge was the more simple part: first, I used the QUARTER and DAYOFMONTH functions to extract the necessary date parts from the SELECT part of my query. Then, having inlcuded all the other necessary fields, I used a WHERE funnction to simply filter out any Order IDs below 11, thus eliminating the first 10.
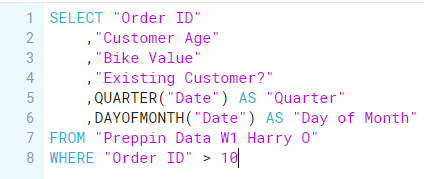
The tricky part (taking up a good 45 minutes of my time and a copious amount of caffeine) was working on the "Store - Bike" field. Splitting the data within was the first challenge, but using the SPLIT_PART function, I was able to select the part of the string to extract, as well as repeat this function for both the "Store" and "Bike" parts. The real challenge was then to group the spelling errors. In the "Bike" fields, the different bike types (Mountain, Road and Gravel) all came with spelling mistakes. After some hair pulling and contemplating using REGEX (only as a last resort), I ended up grouping by the lengths of the strings themselves, as thankfully each bike type had different character lengths. Finally I had completed Challenge 1!
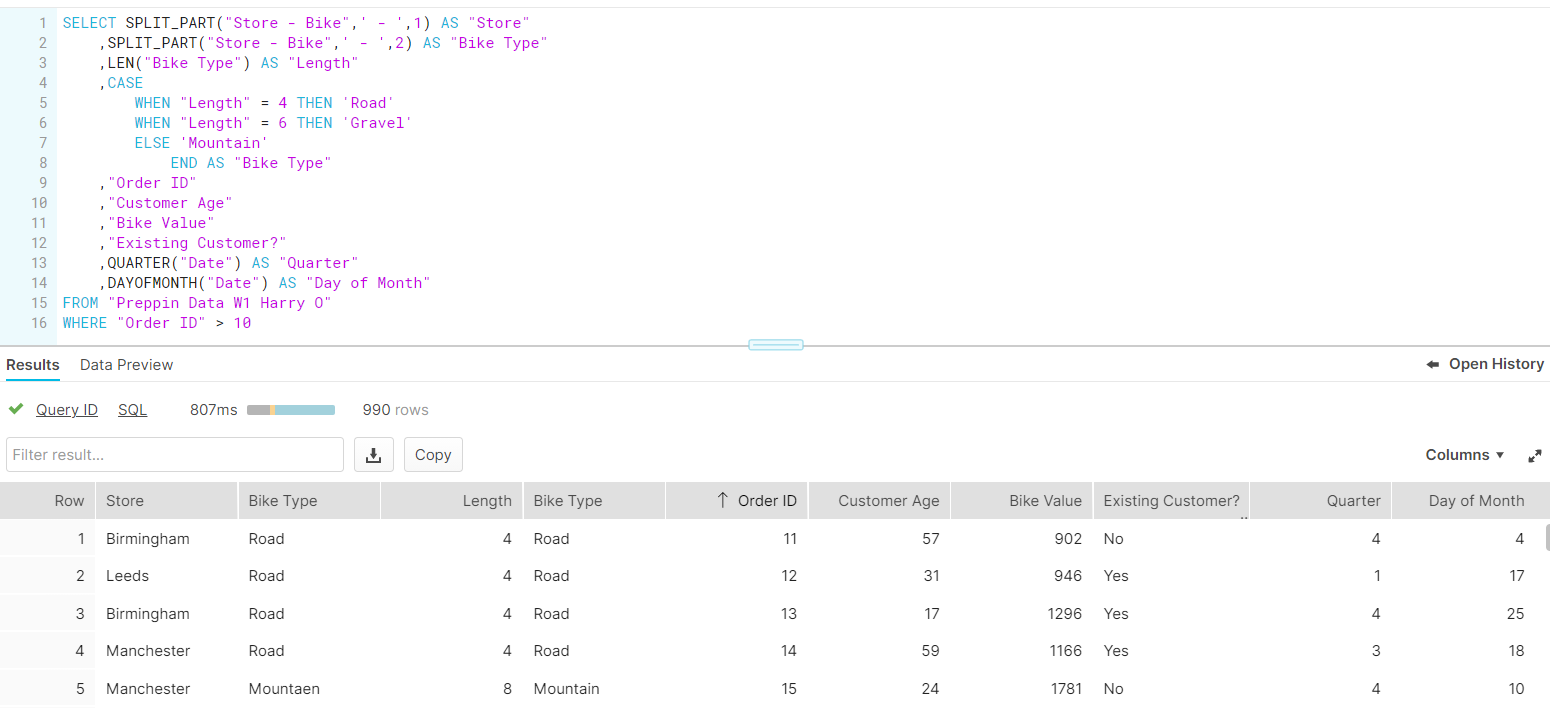
Preppin' Data 2021 W2
Week 2 was marginally simpler, as the issue of cleaning fields was not present here. From the starting data, the task was to creat two outputs, one for details around the Orders and Bike Values, the other to show Avg Days to Ship.
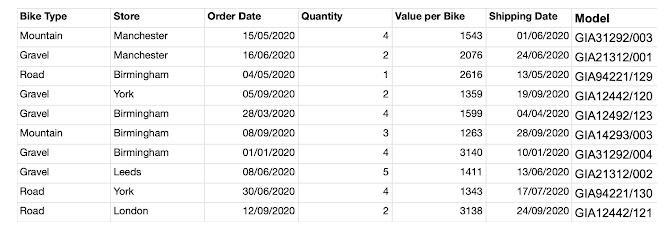
The new problem was removing characters from a string altogether: our "Model" field contained numeric characters to be removed, leaving only the Brand (the capitalised letters). This (after more trial and error, colourful language and eventually succumbing to asking for help) was possible through REGEX, although made slightly more tricky by an unfortunate issue with COLLATE.
Using REGEXP_REPLACE to replace all instances of a number with nothing ('') and avoiding the letters (using ^ as an EXCLUDE marker), I was able to extract only the Brand. The issue was then that Snowflake/SQL would read an error, based on the 'Function not supporting collation'. This is purportedly an issue with the data itself, so that Snowflake was recognising the data as something other than the default, and subsequently struggling to REGEX. This was solved with wrapping the function in a COLLATE.
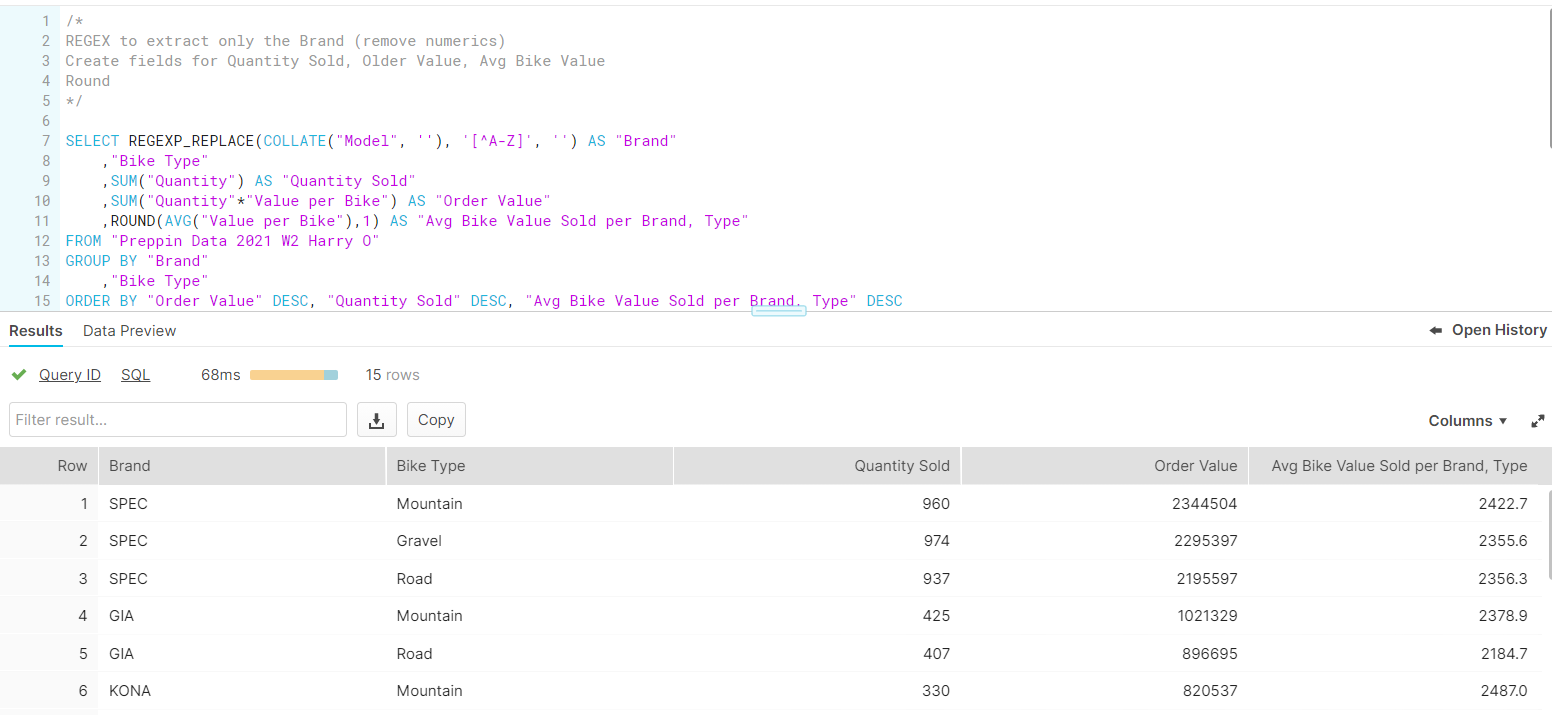
From there, it was more a case of awkward maths to create the final table structure (at the bottom of the image). It is worth noting that I also used a ROUND function on the "Avg Bike Value Sold per Brand, Type" for just 1 decimal place. Part 2 was borderline the same requirements, also asking for the difference between "Shipping Date" and "Order Date". This used a function similar to what many will have seen in Tableau - a DATEDIFF calculation, again rounded to 1 d.p., and calculated as an AVG rather than a SUM. Both parts done, two weeks down!
Preppin' Data 2021 W3+W4
Week 3 continued the theme of unrelenting despair, misery and pain by asking to union 5 tables (all from different store locations), and then pivot the data to begin splitting and analysing. Pivoting, however, is a pain in SQL; not only is it very clunky to work with, but the UNPIVOT function (columns to rows, what was required) is arguably even more fiddly. Luckily through some of my patented "Do Whatever You Can Conceivably Think Of"™, I managed to fumble may way to a pivoted table!
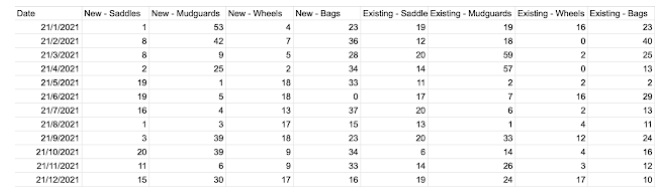
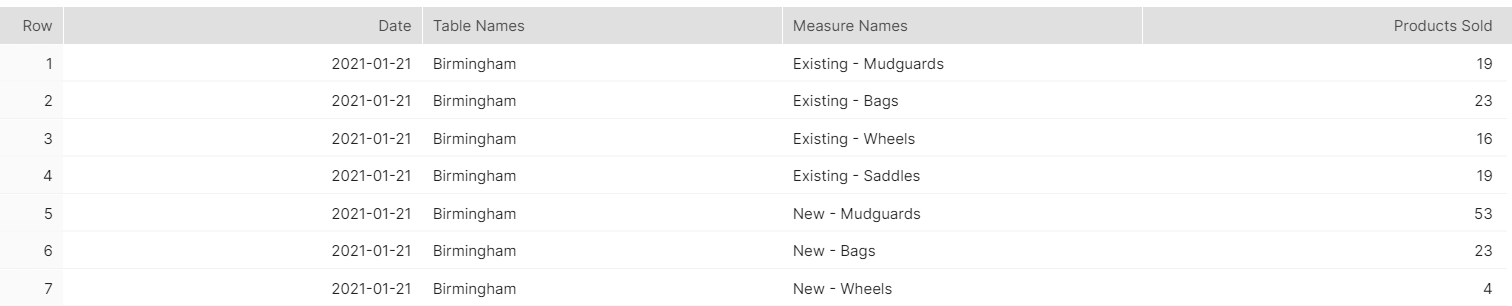
Then, like a burgeoning gymnast on the path to Olympic glory, it was time to do the SPLITs yet again. Similar to the functions used in Week 1, I recycled my SPLIT_PART almost term-for-term, subbing in my new "Measure Names" field. This created two new columns ("Customer Type" and "Product Name"), both of which were mercifully clean and mistake-free. At this point I took a breather, had lunch, and then returned to run the SQL/Snowflake gauntlet once more.
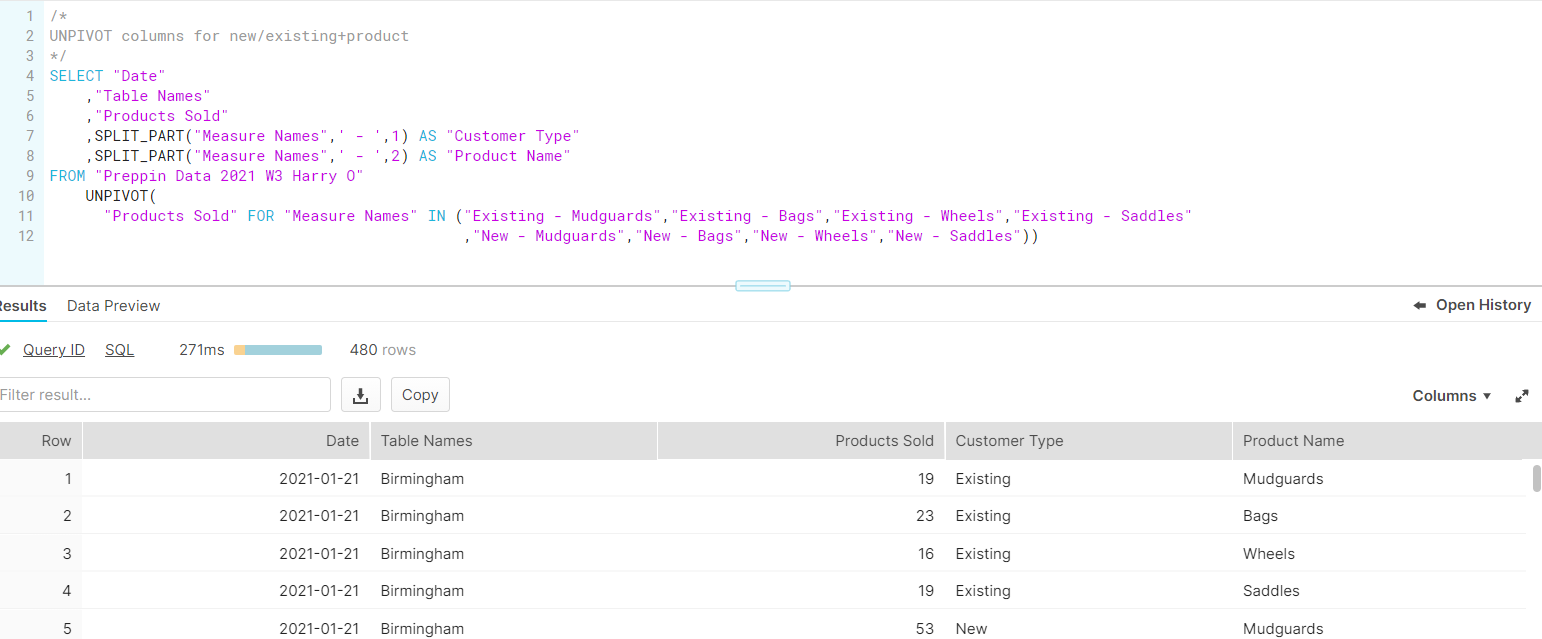
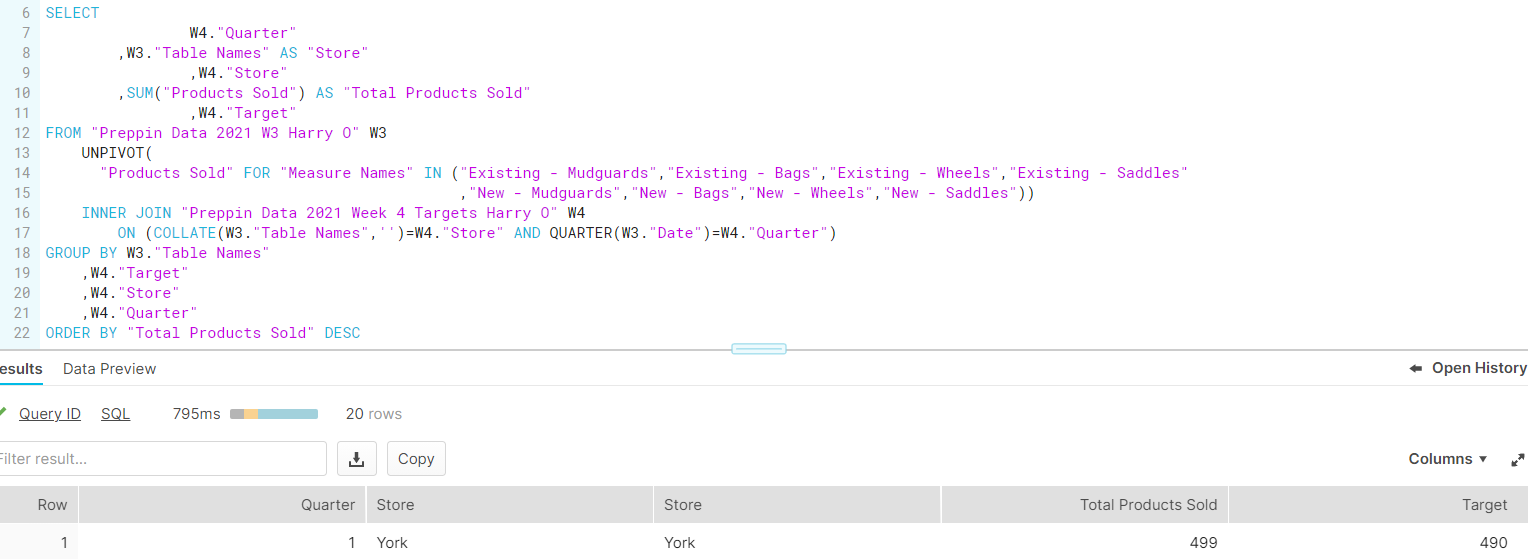
I realised after my break that there was very little else to do with this part of Week 3, bar some calculations I had done for previous weeks in this challenge, so I input those, and continued onto Week 4. This was a slightly different beast, as it relied upon a JOIN clause (i.e. appending two tables to one another based on a common field). This was using a "Targets" dataset that contained Store Locations and Quarters (hence the fields to create joins on, given these were in my Week 3 output also).
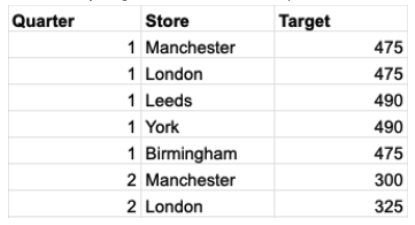
The JOIN clause was disgustingly fiddly, working off prefixes that assign each column used to its original table. I used "W3" to denote fields from the original Stores table, and "W4" to describe fields from the Targets sheet. This useful for my own visual cues, but made troubleshooting and creating a solution a minefield, plus stuck on an issue involving duplicate rows (even though I specified JOIN clauses to prevent that...). This resulted in me running out of time still stuck on Week 4, but happy with my overall effort!
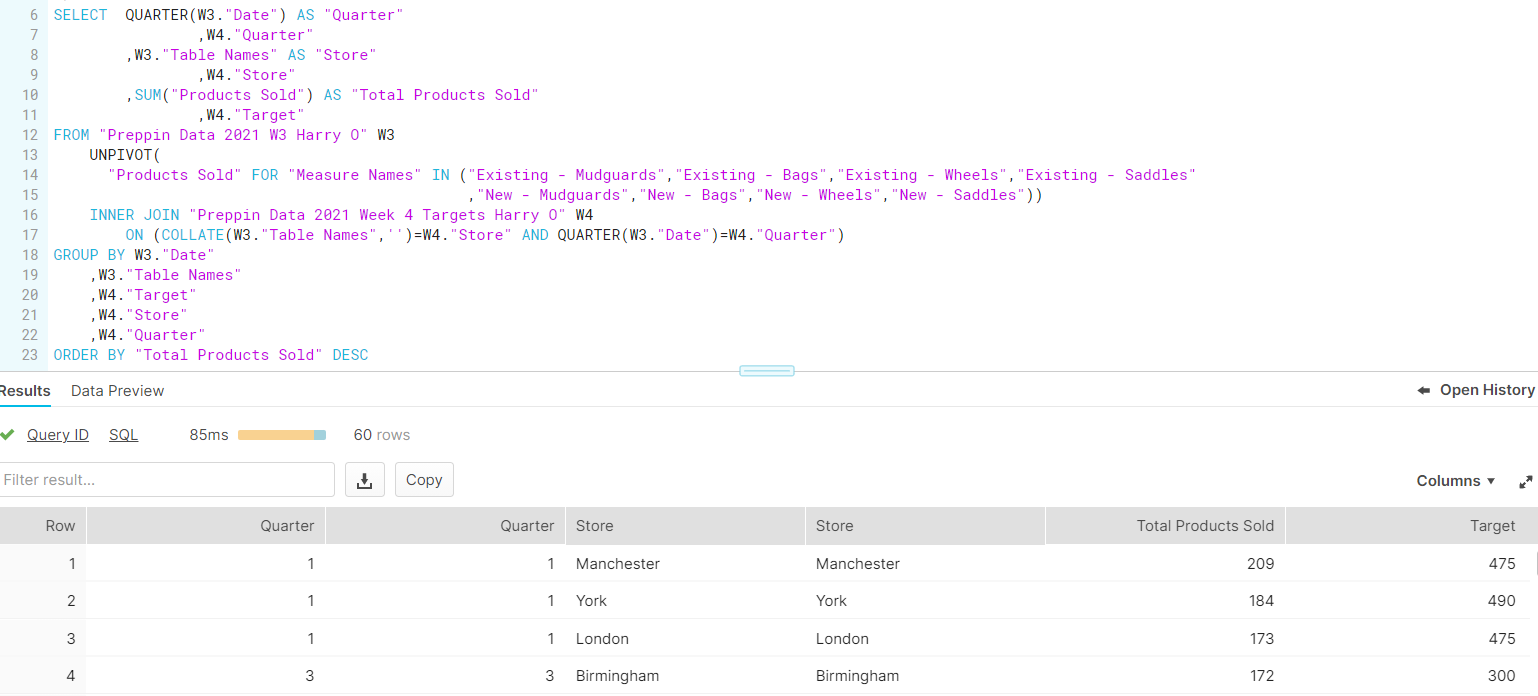
SINCE PRESENTING: turns out my issue was actually to do with my W3."Date" functions being included, when W4."Quarter" would have done the job on its own! Thus, by removing this field from both the SELECT and the GROUP BY, my whole query worked. All in all, a good day of SQL and Snowflake!