


1. Is Data Interpreter allocating headers incorrectly?
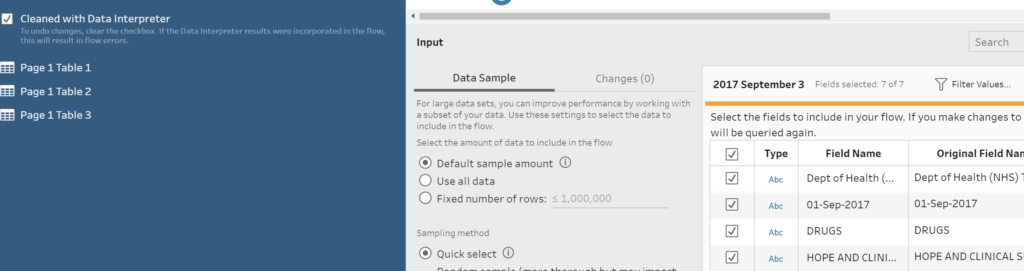
If a pdf is connected and has multiple tables within it, Data Interpreter may hinder rather than help you. In the picture below you can see that the “Field Name” columns are taking the information from the first row of the table rather than headers or placeholder header (F1, F2, etc).
This happens when a pdf is formatted to have the headers on page 1, but pages 2 onwards do not have headers. Hence, data interpreter takes the first row of page 2 etc as the headers.
Solution: Do not use data interpreter in these cases, rename headings manually.
2. Is Tableau Prep Builder recognising all the data in the PDF?
Sometimes data is saved to a pdf as an image. This means that Tableau Prep Builder cannot recongise the data in the table.
In my pdf data set there are two entries on different dates for CORONA ENERGY LTD:

However when I look at the same table on Tableau Prep Builder it tell me there is only one:

Solution: In this case it is difficult to resolve. The easiest solution may be to access to the data from a different file type if possible
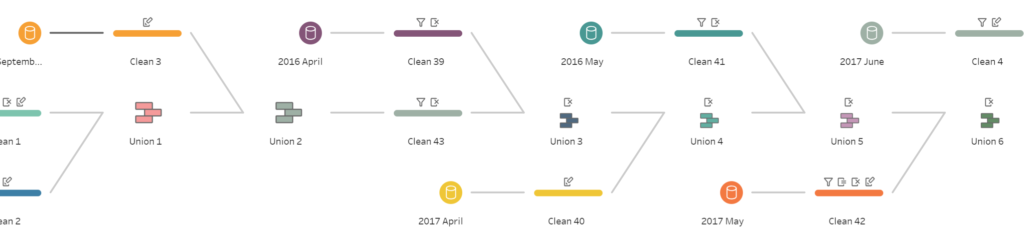
3. Lots of tables = lots of unions.
When importing multiple pdf’s, or a pdf with multiple pages, you will be required to union them in order to output a single table.
This means that you will need to union these tables. In my example below I have several tables from different pdf’s and a few tables within several of them. This meant I had to clean AND union the tables. This was very time inefficient.
Solution: I’m unsure which is the best solution yet! Patience? If you know of an easier way to deal with pdf unions tweet me @jamf_data