


We were told to web scrape via Alteryx data about Parliament House Rules. There was a CSV available, but naturally Andy did not let us use this.
The first step was the Download tool to download the HTML into Alteryx.
Obviously, the HTML code would not be ready to analyse straight away, the code would need to be taken out. A great way of doing this is using RegEx.
Using Google Chrome, you can ‘Inspect’ the webpage, which will show you the HTML underneath that webpage. I wanted Alteryx to only give me the actual date, not HTML code.
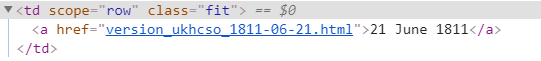
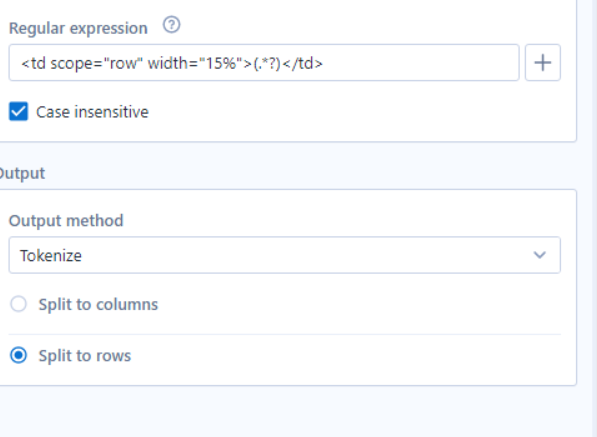
I therefore used the Tokenize output option in Regex to only show me what was in the bracket (.*? will give me what is in the bracket), and it would output what is in the brackets every time this section of text appears (as this set of code would appear for every separate date on this webpage). I then split this to rows, giving me a new row for every time it was split.
Along with a few other steps on Alteryx, it then gave me the data that was ready to analyse on Tableau, which looked the same as the raw version (phew…)
By the time I got the Alteryx workflow working, I did not have much time to complete my dashboard. I also wasn’t sure of any interesting insights of the data.
I ended up looking at word count, seeing the maximum word count for each date and also showing the distribution of how many rules were in each word count bin (ie how many rules were in the 25-50 range for example).
Hope for a better day tomorrow.