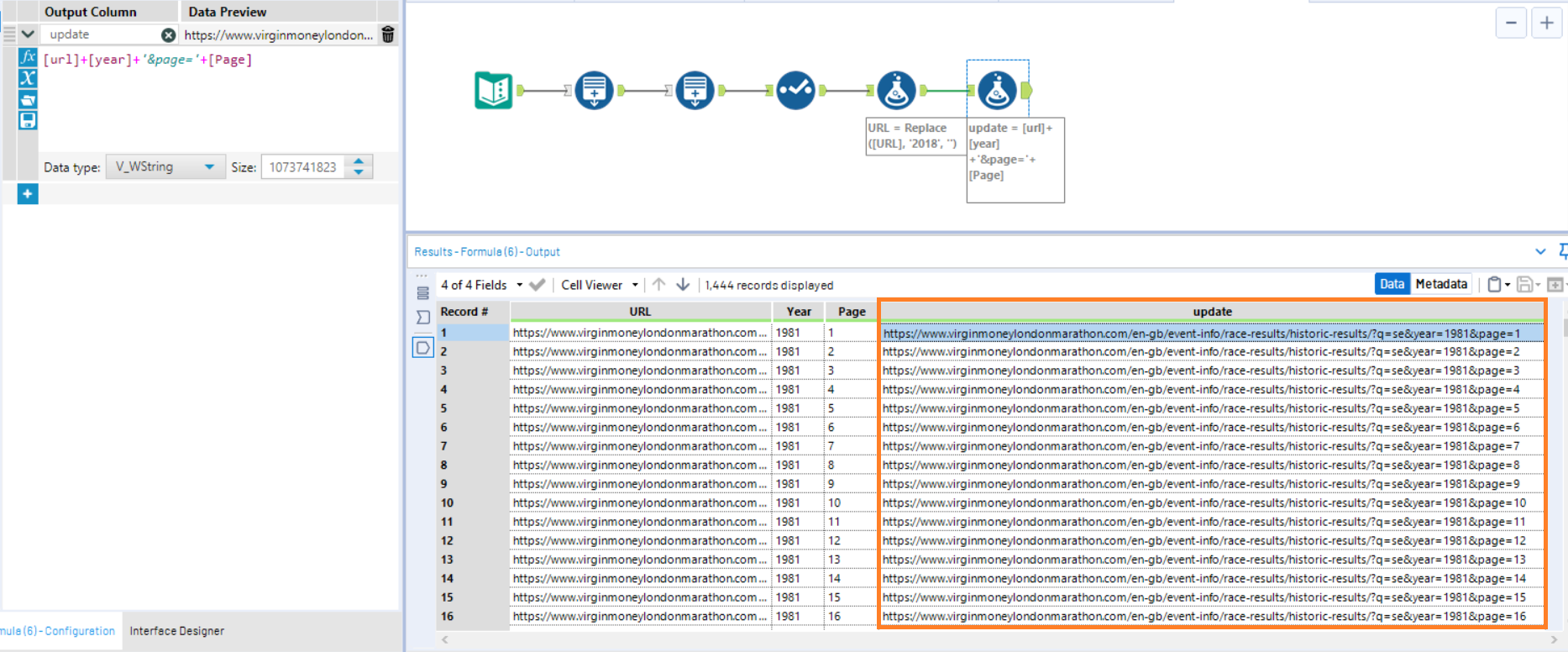
Second assignment: retrieve all the data for every year for all participants in the London Marathon using the below website.
https://www.virginmoneylondonmarathon.com/en-gb/event-info/race-results/
We had to collect all historical data for all participants that had the same initials as ours; my initials had to be SE, for some reason Kriebel said I could not do SM.
After searching for participants with my initials in 2018, the following URL shows up in my web browser.
I am going to focus on the last few characters of the URL: year=2018&page=1.
I can see that following the first = in the URL, 2018 is entered, so that means when I when scrape the website using Alteryx, I would have to change that to include all years since 1981.
After the second – in the URL, 1 is entered, which also means I will have to change that to include all the other pages when I scrape the website on Alteryx.
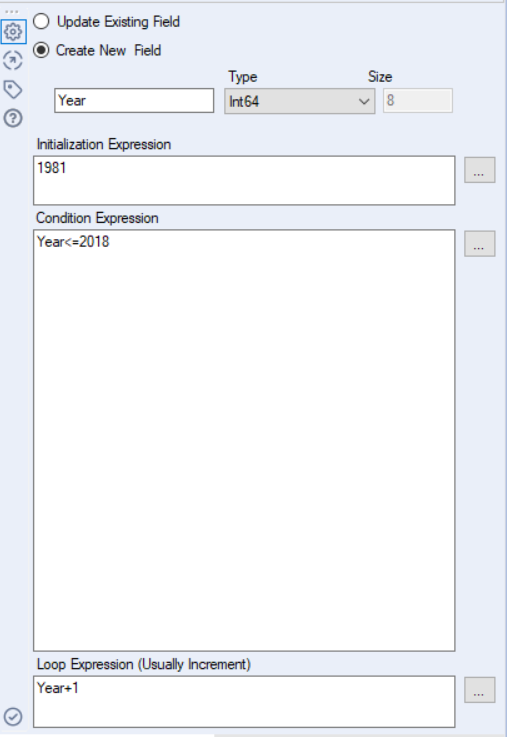
To do this input a Text Input tool into the Alteryx canvas and enter the URL mentioned above. Then, insert a Generate Rows tool after that. See Image 1 to see what to put in the tool. This will generate rows for one column (titled Year) and will give values of 1981 – 2018.
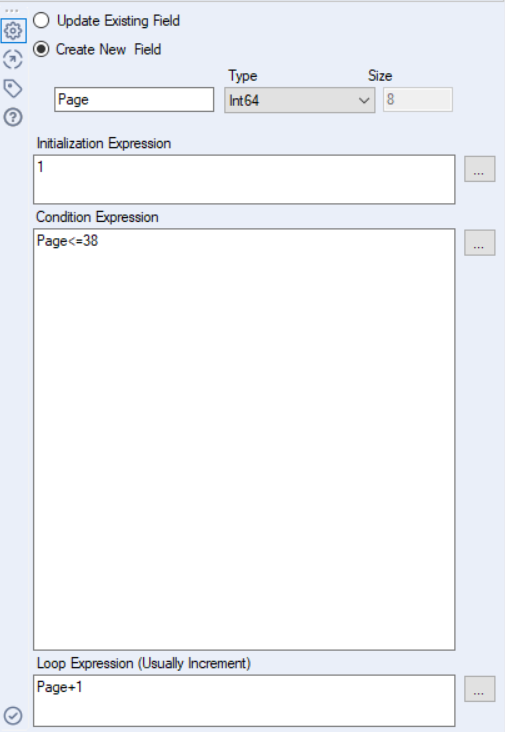
After that, insert another Generate Rows tool onto the workflow and see Image 2 to view what to put in the second Generate Rows tool. This will generate rows for page numbers up to 38 (random choice) for each year entry.
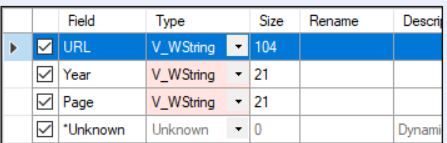
Add a Select tool and change the Year and Page column types to V_WString, see Image 3.
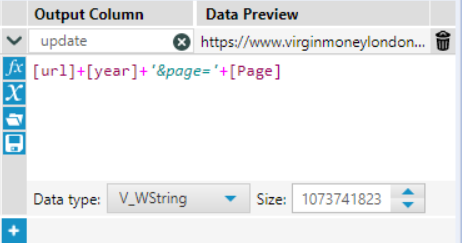
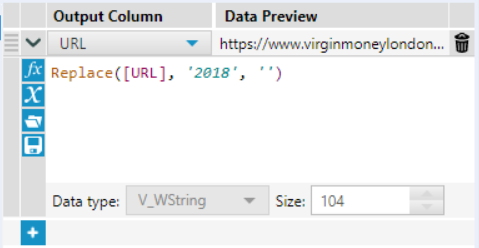
Attach a Formula tool and replace the last four string characters (i.e. 2018) with a space as shown in Image 4.
Lastly, insert another formula tool and add new a column titled ‘update’ and follow as seen in Image 5.