


Webscraping can be a very powerful tool. It allows users to ‘scrape’ a website for the public data displayed on the site. Rather than having to manually note down figures or words on the site, software tools can be used to pull this data from the page source code and sort it into a usable format. We recently learnt to use Alteryx as the software tool of choice to webscrape by learning to scrape our own Data School website (https://thedataschool.co.uk). We were tasked with using the source code of the site to find our names, bios, pictures and blog links. We used Alteryx to go from:
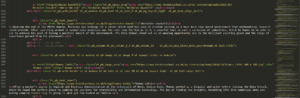
To:
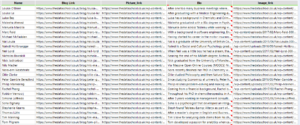
To start, a text input tool to input the website we were wanting to scrape, in this case /team/. If the user is wanting to scrape different pages of the same site then this input can be used to set up the multiple sites, as we ended up doing as a Friday project. The Download tool is then used to download the page source code as a string to be used to extract the data. The download tool will create two fields, the ‘DownloadData’ field which contains the source code (this long string can be viewed through a Browse tool) and the ‘DownloadHeaders’ field which will indicates whether or not the download has been successful. If successful DownloadHeaders will have the display ‘HTTP/1.1 200 OK’, after the download is known to have worked this field can be removed as it is of no more further use. The source code of the website will be downloaded all in one block, so the block has to be broken up into rows in order to be used. The Text To Columns tool can be used to do this, selecting columns to split as DownloadData and selecting ‘Split to rows’ will split the block into rows using a delimiter. A good delimiter to use is ‘\n’ as this is the command used to start a new line in the source code, however any delimiter can be used if more useful. A useful thing for later will be to add a record id to each of the rows, this is because the method of extracting the data will lose the structure of the source code, so this record id will allow information to be grouped back up when needed. These tools will then get the source code to:
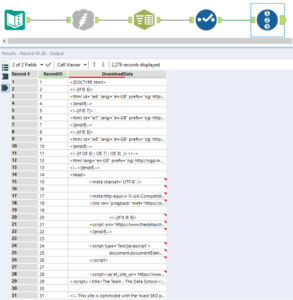
A lot of the rows of code will contain leading whitespace as it is used to structure the source code, so the Data Cleansing tool can be very useful in tidying up the DownloadData field. Then using a notebook text editor the source code can be inspected for patterns within it. For example the line with the blog link and person’s name in our website source code begins with ‘<h2>’ and ends with ‘</h2>’ where few other lines include both of these:
![]()
So a filter in the Alteryx flow can be used to separate these rows within the code from the rest with the custom filter: Contains([DownloadData],'<h2>’) and Contains([DownloadData],'</h2>’). Once these lines have been separated from the rest some tidy up needs to be done. Some lines will be unneeded as they don’t contain the information that is of use and some parts of the string will no longer be needed, such as the ‘href=’ in the line shown above. In the case where there are two pieces of information are both in one line such as above, the Text To Columns tool can be used to separate these two pieces of information into different fields. Here the delimiter can be ‘”‘ which will separate the string into two fields. Cleaning up the rest of the syntax around the information and renaming the fields gets:
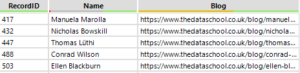
The other bits of information within the source code will have similar unique ‘tells’ to them which can separate them to be cleaned up to a usable point. Once the all pieces of information that are desired have been found, separated, cleaned and formatted the different fields of information can be Union’ed together using the Record Id field. Using the record id as the union will then restructure the lines of code back into the order in which they originally appeared minus all the code which is not needed. After being union’ed together there will be rows of nulls where some fields have data and others do not, like so:
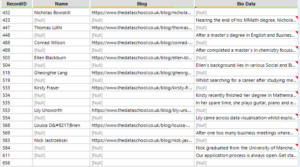
Ideally each set of information would be on one row, however the union has brought it together in chunks. Sometimes these chunks will follow a set pattern (as this one appear to do for the first few lines) but other times there might be an irregular pattern, for example here where most have one line of ‘Bio Data’ where others can have more. There are many ways to then sort this information onto one row but a very good way is to create a field that gives each chunk of information a value so the chunks can be grouped using this value. The each chunk should have a starting tell, here it is that the Name field is not null, so a Multi-Row Formula can use this to assign a number to each person’s details. The Multi-Row Formula can be set up like:
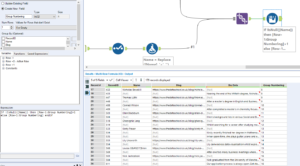
With the formula: If !IsNull([Name]) then [Row-1:Group Numbering]+1 else [Row-1:Group Numbering] endif, will give the group numbers required to group information together. Since the sections have a grouping field the record id is no longer needed so can be dropped from use. Now a Transpose tool can be used; by selecting the Grouping Number a Key Field and having the fields of information as the Data Fields the pieces of data that are of interest are put into one field, the Value field, and their role titles are within the Name field. The grouping number will be replicated across all the rows which it was attributed to, so the grouping is still held.
![]()
A filter can get rid of all the Null values in the Value field which leaves only the relevant information, all within one field and grouped by a number for each person.
![]()
Now a Cross Tab tool, with the Group Numbering as the Group Data by these Values, Name as the new column headers and Value as Values for New Columns, will get all of the wanted data into one row. The field headers should be as desired however can be changed if needed. Now the grouping number is no longer of particular use so can be dropped but are able to be used as an id for each person if wanted.

These techniques can be repeated for most websites that display data, the details will change given the structure of the page source code however the process should work for most. As mentioned earlier we also downloaded our images so this will be the topic for an upcoming blog post as this one has already gotten rather long!