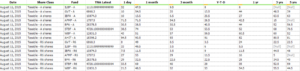
You will often get into a position in which you will have to spend some time on cleaning the provided data before you can perform actual analysis on it. Take the following example:

The date in the first row of the first column is quite common for an excel-sheet. It probably serves as time stamp for the sheet. Also, the rest of the data looks messy. There are a lot of null values and the first column “American Funds Fixed Income…” contains string and float values. To perform analysis, we probably want our data to look more like this: 
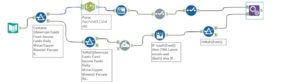
To achieve this result, we could create the following workflow:
First step: Isolating the date field with the filter tool
With the formula Contains([American Funds Fixed Income Funds Daily Mstar/Lipper Blended Percent Ranks],”Ranks“) ,I can isolate the date.
Second step getting rid of null values:
If the filter is not true, meaning it does not contain the date, all rows, except the first one, are returned. Since the new first row contains only null values, I filtered it out as well.
Before:

After:
Step 4: Make the first row headers with the dynamic rename tool

Step 5: Create a new Share Class column with the string values of the TNA latest column
With the multi-row-formula we can extract Taxable Shares information from the TNA latest column.
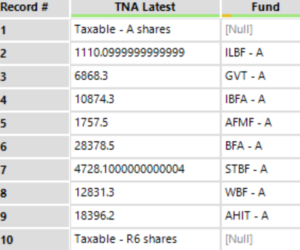
The logic is that if Fund is null then we copy the corresponding value of the TNA latest field into our new Share Class column. The prior row value of the new Share Class should be repeated till a new null value appears in the Fund column. The formula is the following:
IF isnull([Fund]) then [TNA Latest month-end ($mil)] else [Row-1:Share Class] Endif
This gives us the following result:
Step 6: Filter out remaining null values in Fund column
Step 7: Parse the date with RegEx
Now we have prepared one stream of our workflow. Let us now return to the first filter tool and follow the true branch in order to prepare the date.
![]()
Our goal is to extract the date part after ranks of and parse it into a new column. The RegEx tool can help us with that. The expression (\w+\s\d{1,},\s\d{4}) filters out this exact part and extracts it into the next column RexOut. The expression works the following:
\w+\s -> extract the part with all characters and white space (month name)
\d-> extract the part with one or 2 digits (days)
,\s\d{4})-> extract the part with the comma and the 4 digits (year)
The result is the following:
![]()
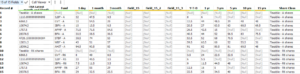
Step 8: Clean null values with the auto field tool and dynamic select
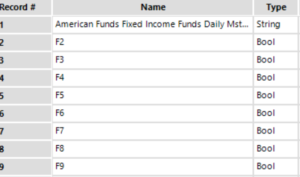
We can get rid of the null value with the auto field tool. Null values are often created by accident if somebody created blanks in an excel sheet by accident. We can avoid this problem in the future with the following trick. The auto field tool assesses all field types of all columns. All columns with null have the type Bool.
With the dynamic select tool, it is possible to deselect columns with an unwanted data type. If we do so, all null values are deselected and even in the future, might the next data input contain additional columns with null values, will be filtered out. 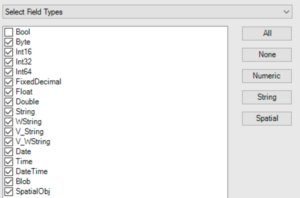
In the final step, we append the date field.
We just need to append the date with the append field tool to the already cleaned table of the first part of the work stream. This will add a date column to the table with a reoccurring date entry in each row.
The final result does not look like a nightmare anymore!