


I was a little confused as to which of these tools to use and so I assume other people may be a little confused too. But have no fear.. the difference is straightforward and easy to understand.
The Join Tool
The join tool matches selected incoming fields from the L and R inputs. The J output will show the rows that do match, the R output shows the rows from the R input that could not be matched with the L input, and vice versa.
We have three options for joining datasets via the join tool:
- Single field
- Multiple fields
- Record positions
We might want to join by multiple fields if, for example, we have a list of first names and last names featuring repeating first and or last names. We only want to join the unique combinations of first and last names, as many people share first names or last names, as per the example below:

By joining on first name and last name we eliminate unnecessary duplicates.
Joining by record position will stick the R dataset onto the L dataset, matching each row simply by their positions.
Append fields
The Append field performs a cartesian join on both incoming datasets; joining every row of the S (source) table onto every row of the T (target) table, as shown below.
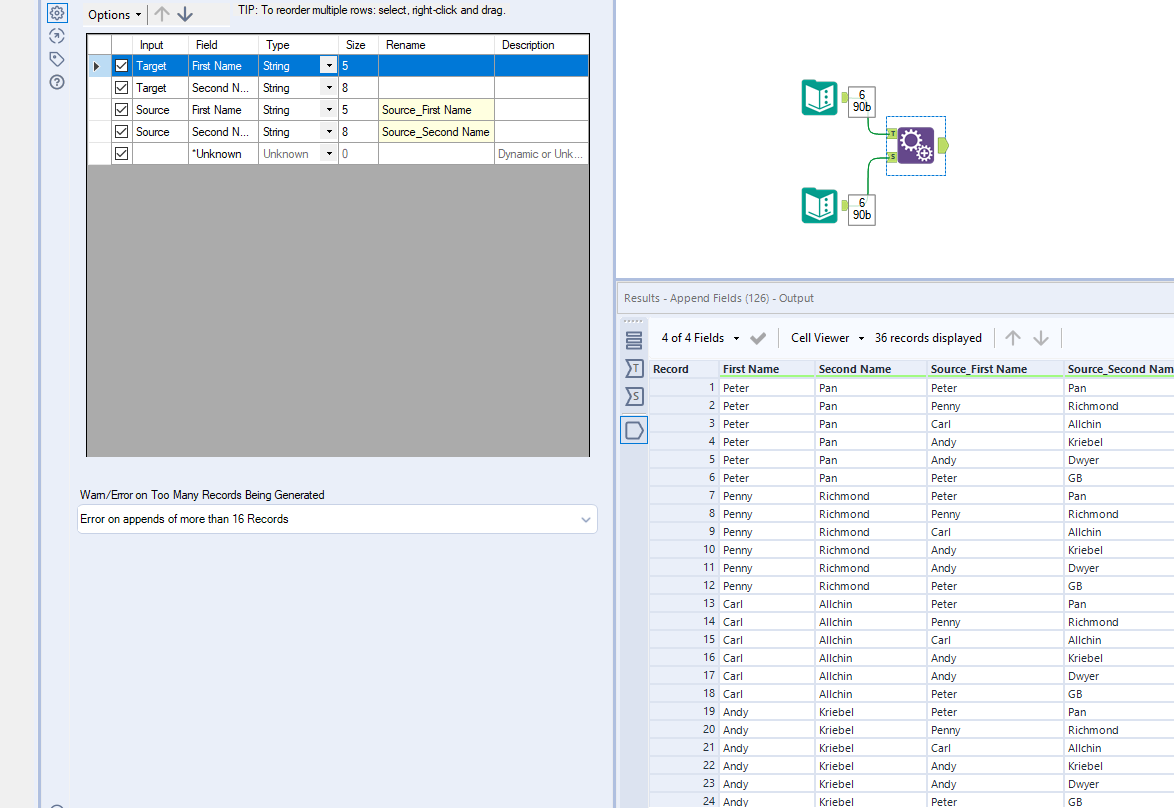
The number of joined output records will be (number of records in S table) x (number of records in T table). This must be approached with caution as we can potentially end up with very large datasets that are slow to process and take up a lot of space.
Similarities:
- Both tools will make the dataset wider
- With both tools we can reorder fields
- Select and deselect fields
- Modify the data type
- Rename fields
Differences:
- The Append fields tool has one outlet.
- Join tool has three. In the J output it will only output those fields that match each other based on selected fields in configuration.
- The join tool is case sensitive, where as case does not matter in append fields.