DS21 focused on Alteryx this week. We covered three main topics during the training sessions – Transpose & Crosstab, RegEx and Multi-Row tools, and our project task for Friday was to complete three of the Alteryx weekly challenges (found here), to cover each of the topics. I decided to start with the RegEx challenge as having studied a lot of linguistics at university I found working with words and word structures particularly exciting.
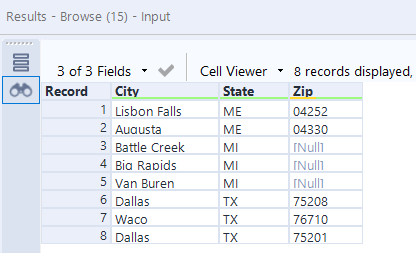
I chose challenge #54. The dataset is a small list of addresses and the goal is to produce a table containing the city, state and zip code in three separate columns. The main problem is that there are no commas or any other delimiters in the original text, which makes it a little more complicated to parse out the required fields.
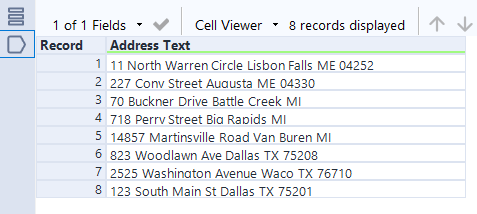
I decided to start with what I knew I could do easily – isolate the state and the zip code using two separate RegEx parse tools. The state name is a combination of two capital letters following a space, which can be described as \s(\u{2}). The zip code is a sequence of 5 digits following a space, which I described as \s(\d{5}). The nice thing about the RegEx parse tool is that it allows us to rename the output fields in the same step, without having to use a separate Select tool.
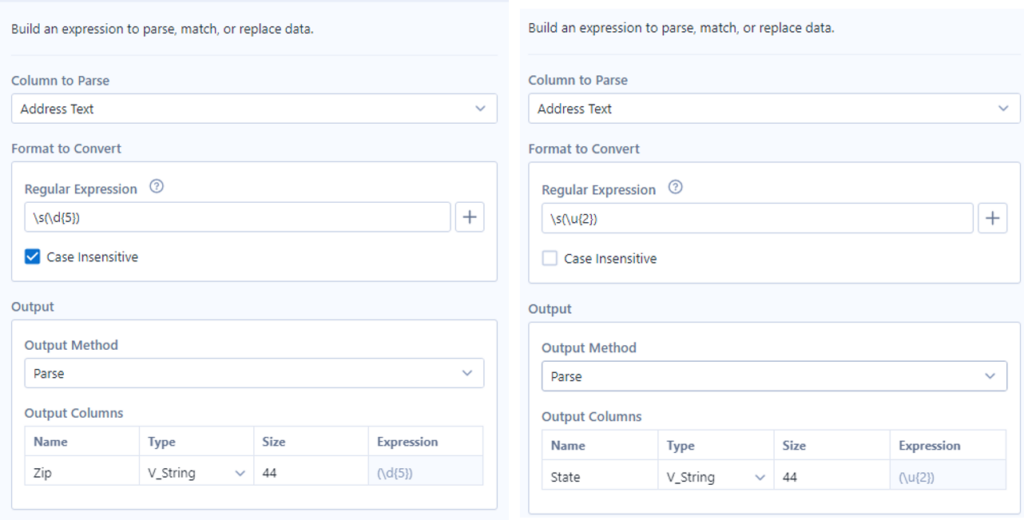
These first two steps were fairly straightforward but the problem I encountered then was how to explain to Alteryx where the street address ends and the city name begins (I had to peak into the solution file to get a hint on this step). Essentially, the idea is to input a separate list of possible address suffixes and include any delimiter after them (I used a pipe |), which would enable us to use the Text to Columns parse tool later (Note that the list could be a lot longer if we wanted to include all the possible address suffixes in the US for future use).
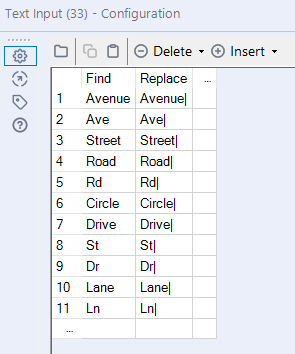
Then, use the Find and Replace tool to change the address suffixes in the original Address Text field and split that field into two columns based on the | delimiter. I then used the Data Cleansing tool to get rid of the leading spaces in the new field and another RegEx parse tool to get the city name. In this newly generate field, city name is everything that comes before the zip code (which is the 2-capital-letter sequence), so we can use the following expression: ^(.+)\s\u{2}. We can rename this field as City and add a Select tool afterwards to get rid of any unnecessary fields.