


It’s been a busy few days here at DS HQ
The DS9 squad are all taking the Tableau Desktop Qualified Associate Exam. DS10 has just kicked off (welcome, guys!). We’re imminently moving to a new home to accommodate our growing family. It’s all go.
What better time to get stuck into
Dashboard Week
If you’ve read Andy’s post you’ll know what it’s all about. If not, we get a new dataset daily and work to clean, prep and visualise it. We present our work to our peers the following morning. We create a blog post detailing what we did. We repeat. Hard core.
We kicked off today with the results of the recent Prudential Ride London 100. Our own Carl Allchin took on the full 100. I got involved and did the 46 mile route…didn’t really fancy the hills if I’m honest…
I was a little late to the party this morning because of the QA exam. It went well though. Things kept getting better as I arrived with the rest of DS9 to find them well on the way to creating a workflow to ‘grab’ the results from the webpage. For this, we use Alteryx.
Luckily, DS9er Alex HW is a bit of a whiz in web-scraping and data cleansing in Alteryx. His brain is at the heart of this workflow, supplemented by little nuggets of wisdom from each of us. That’s been one of the great things about today – sitting around a table working together on a single problem. With client projects we generally split off into pairs. It’s a nice change of pace.
Now it’s time to get into the nitty gritty.
Getting the data
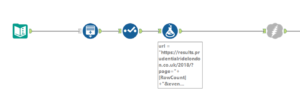
Here, we offer Alteryx the first page of results from the Ride London site. We know that there are actually more than 1000 pages to scrape so we tell Alteryx to begin at row 1 (page 1) and continue scrolling through rows (pages) until the maximum is reached. We use the download tool to ‘get’ the data from the website to our machines.
Cleaning the data
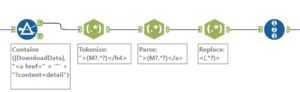
We perform a number of steps to get the data into a readable format. This involves using regular expressions (regex) to get the text that we want from the text that we don’t want. We can use html tags like <h4> or </h4> as flags to help the regex identify the things we want.
The same set of steps are performed for the other cells identified as columns – cycling club, distance, age group.
Next up, we join the dots – join these multiple streams back into one stream using the row id (created in the final step on the right hand side in the image above).
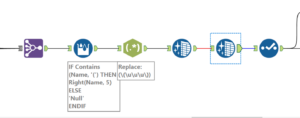
The final stage in the workflow tidies things up a bit and gets rid of any of the columns that we no longer need. We’re then ready to export our dataset as a tableau hyper extract. This can be read easily (and performs efficiently) in Tableau Desktop.
Telling a story
I’m a person who rides a bike. I know from whizzing around on 2 wheels that it’s a male dominated pursuit in London. I know that there’s gender inequality in the sport of cycling (like many others). I know that there’s a certain type of person that spends a lot of money on the gear and talks cranks, carbon, and criterium while also being of a certain age. Yeah, it’s the MAMIL.
This might not mean much to you, but that’s what my dashboard is for! Explore the term and what we can say about it by analysing the Ride London data.
Here’s the link to the finished product!
If you like, hate, or want to change something find me on Twitter @AdiBop_
See you all tomorrow. Same bat channel.
