


Broad Strokes
Following on from Laura’s posts about Decision Trees and Time Series Forecasting I thought I’d jump on the predictive analytics bandwagon. I’ve made an Alteryx schema which will hopefully help any of you wanting to exploit the power of predictive analytics. What I’ll show below is supposed to be a guide for how you might want to set up your own workflow, and so I’ve tried to make it as broadly applicable as possible. Because of this I’m not going to go into much detail about how tools are set up or what they output.
My schema is based around the comparison of several predictive models. In order to do this, you’ll want to have the Model Comparison Tool which can be downloaded from the Alteryx Gallery here.
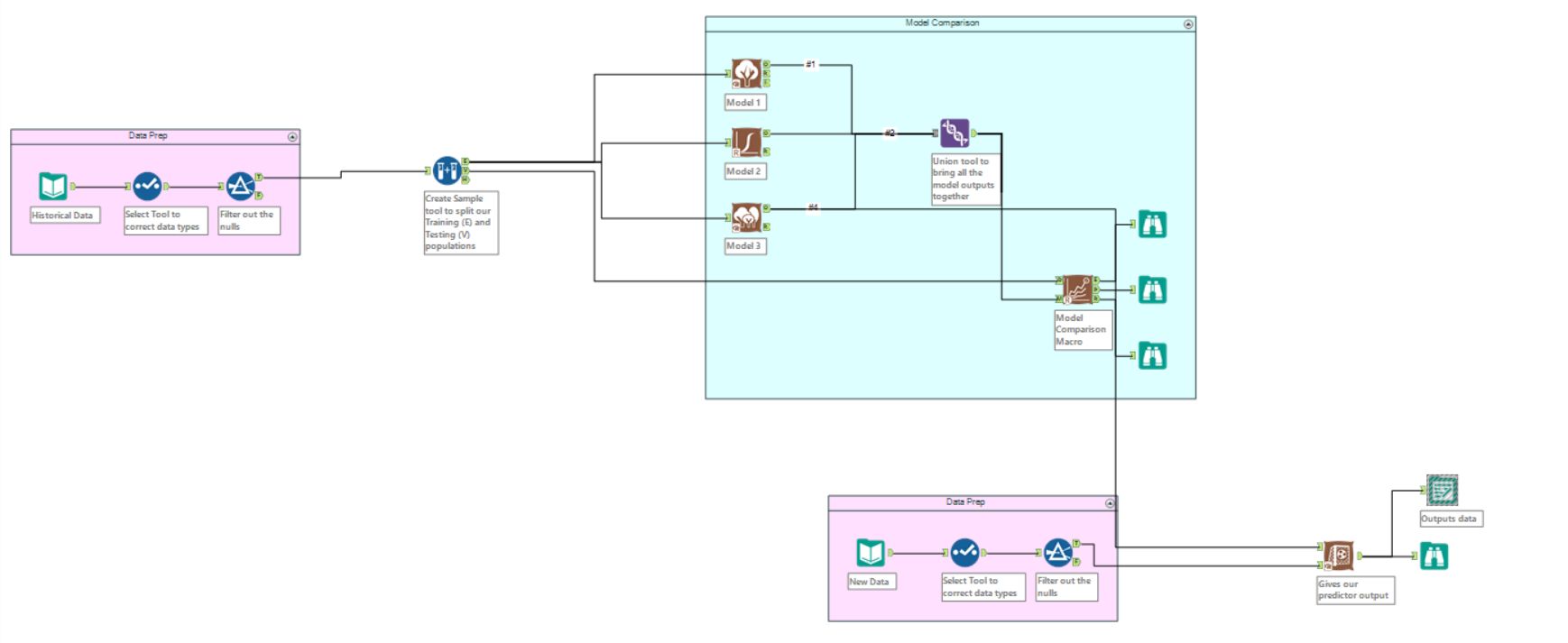
The full workflow
Inputs
So you’ve got a bunch of historical data, as well as some new, and you want to see if the old can tell you something about the new. Maybe you have the profiles of all your previous customers and the demographics of a proposed new location and you want to know what type of products to stock in the new store. The predictive analytical tools in Alteryx are here to help! They can take predictor variables (in this case the demographics of the consumers) and see if they account for the target variable (maybe most popular product).
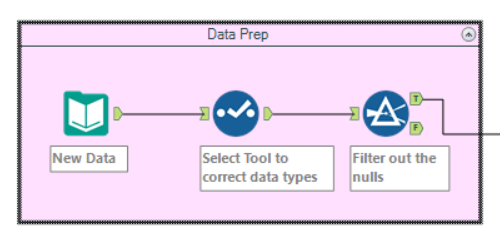
As with most things in Alteryx, our first step is to clean the data. We firstly want to make sure that all the fields are the right data type. The select tool is the easiest way to check and if necessary change these.
The predictive analytics tools do not play well with null rows, so we need to decide what to do with any we might have. We could populate them with average values, or some other type – or it may be best to filter them out. There are no hard and fast rules for these questions, as per it depends on your data’s individual needs. For my schema, I’ve chosen to filter them out.
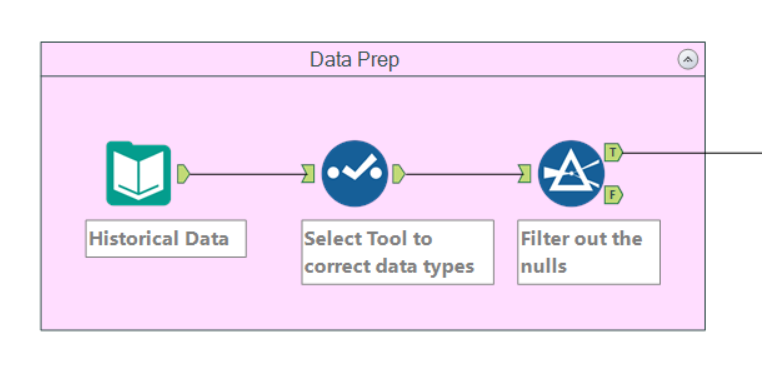
Sampling
The next stage of the schema is to create a sample. To explain why, I’m going to steal Benedetta‘s metaphor. Let’s imagine the modelling tools are students. We need to teach them a topic (our historical data) and then test their knowledge on it. However, if we test them with exactly the same material as we trained them, then we’re not testing them very well. If you know exactly what questions are going to appear on an exam before you take it, then you can memorise the answers without understanding them at any point. Likewise we need to train our models on a set of data, and then test those models with a similar, but not identical set of data.
We can use the Create Sample tool to split our data into two randomly selected segments. One (E) we use to train the models, and the other (V) we use to test them. The proportion of these sets depends on the size of your data – your main constraint will be making sure your testing set is large enough for your models – but a 70/30 split is not a bad place to start. 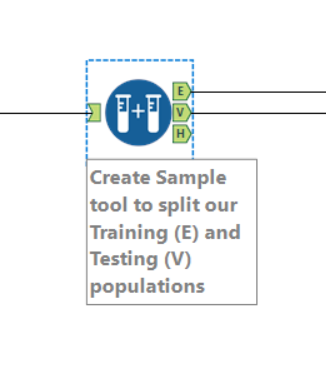
Comparison
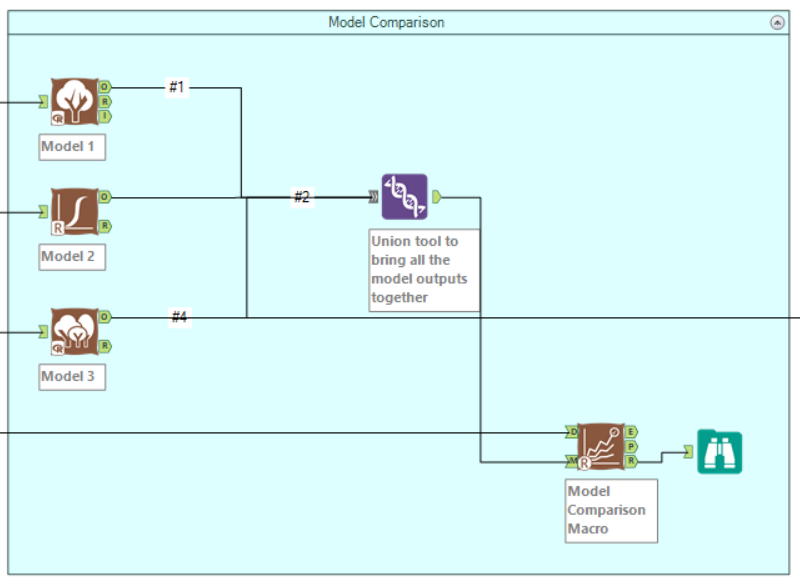
Next up we want to try a number of different models to find the one that is most accurate for our data. Which models you use is entirely dependent on your data and the questions you want to ask of it. Whichever ones you choose, take the E output from the Create Sample tool and connect it to their inputs. Set them up, choosing your target and predictor variables. You can then use a browse tool on their R outputs to view in depth reports on each model. We want to compare the models so first we need to union the outputs of each model. We then take the result of this union and connect it to the M input to the Model Comparison Tool (again, found here). To remember which input to use think M for Model and D for Data. Speaking of, we want to connect the V output from the Create Sample tool to the D input. Finally stick a browse on R to view the report of the comparison tool. As a rule of thumb, pick the model with the highest overall accuracy – although depending on your use case, this may not always be true.
New Data
At this point you know which is the model you want to use to predict your target variable in your new data. So now you’ll want to bring in that new data and clean it up like we did before.
All Together Now
We have our trained model. We have our new data. We want to combine them. Or more specifically, we want to generate a value (decided by our chosen model) for a target variable based on the predictor variables in our new data. The Score tool is the one you’ll want for this. Connect the O output of your chosen model to it, along with the cleaned data. This outputs a score for your target variable – say likelihood that a product will be most popular based on the demographics of your new store.
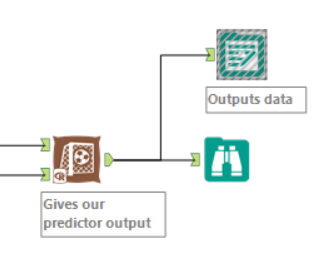
And there you have it. A slightly vague blog post, but hopefully this provides a frame around which you can fit your specific predictive needs. Different models and different data will require extra steps, but I think that every step in this workflow is a necessary one for predictive analytics. If you want to chat analytics or Alteryx with me, then you can find me on twitter.
Full view once more